Nigdy nie powinno się niczego opowiadać, dostarczać informacji czy przywoływać historii, ani powodować, by ludzie snuli wspomnienia na temat istot, które nigdy nie istniały, nie postawiły stopy na ziemi ani nie przemierzyły świata, a jeśli nawet przezeń przemknęły, teraz są już prawie bezpieczne w niepewnej i na poły ślepej niepamięci. Kiedy opowiadasz, to jakbyś dawał prezent, nawet jeżeli opowieść zawiera truciznę, też jest więzią i wyrazem zaufania, a ten kto zaufał, rzadko nie doświadcza wcześniej czy później zawodu, rzadko więź nie gmatwa się i nie zapętla tak bardzo, że trzeba użyć noża lub brzytwy, żeby ją przeciąć.
Javier Marías, Twoja twarz jutro[1]
Wojna w Ukrainie rzuciła nowe światło na relacje pomiędzy technologią, infrastrukturą i geopolityką. Podejmowane przez władze Rosji próby, które zmierzają do odcięcia jej obywateli od światowej sieci, pokazują, że aktualna forma internetu nie jest niezależna od uwarunkowań lokalnych, zarówno politycznych, jak i geograficznych. Eksperymenty z tworzeniem narodowego internetu – wbrew powszechnej intuicji – sprawiają, że granice wytworzone w świecie cyfrowym stają się zależne od geograficznych granic państwowych, a terytoria cyfrowe splatają się z materialnymi. Sieć nie jest jednolita i gładka, jak zazwyczaj o niej myślimy, ale ma swoje „mury”, wklęsłości, zagęszczenia i geometrię[2], które pozostają w ścisłych relacjach z geografią fizyczną, polityką i globalnymi strukturami władzy. Ten splot technologii z geopolityką najlepiej widać w materialnej infrastrukturze sieci, o której często zapominamy lub po prostu nie wiemy, a której istnienie przesłania m.in. charakterystyczny język mówienia o technologiach.
Język, jakim opisujemy najnowsze technologie, podkreśla ich lekkość, zwinność, ulotność, niematerialność. Mówimy o chmurze i wyobrażamy sobie rozproszone w powietrzu, swobodnie unoszące się cząsteczki danych, które nie mają ciężaru ani fizycznej masy i są niepochwytne. Tymczasem internet, chmura czy to, co pozwala nam doświadczać technologii jako „lekkich”, „zwinnych” i „mobilnych”, w istocie opiera się na bardzo konkretnym szkielecie materialnej infrastruktury. Począwszy od małych routerów domowych, przez kable łączące je z większymi strukturami sieci zarządzanymi przez dostawców usług internetowych (Internet service providers, ISP), takimi jak farmy serwerowe i centra przetwarzania danych, przez punkty wymiany ruchu internetowego (Internet exchange points, IXP), gdzie łączą się ze sobą sygnały różnych dostawców, aż po kręgosłup sieci, czyli duże struktury kabli i światłowodów położone na dnie oceanów i mórz oraz przecinające całe kontynenty, przesyłane są ciągi zer i jedynek kodujące wszystkie informacje z naszego świata.
1. Dane nie znajdują się w chmurze, tylko na dnie oceanów[3]
Około 95% globalnego internetu płynie aktualnie po dnie mórz i oceanów. Blisko 400 podwodnych kabli światłowodowych łączy różne miejsca na świecie, pozwalając na szybszy transfer informacji pomiędzy niektórymi z nich, a inne (np. Kubę) odłączając od globalnej wymiany wiedzy, usług i produktów cyfrowych. Niektóre z kabli mają kilkadziesiąt kilometrów, inne, przebiegające przez Pacyfik, kilkanaście tysięcy. Muszą wytrzymać silne prądy morskie, osunięcia się skał podwodnych oraz pracę wielkich trawlerów rybackich. Ich instalacja wymaga ciężkiej fizycznej pracy robotników w fabrykach i na statkach.
Analiza mapy węzłów i połączeń tworzonych w ramach tej sieci pozwala na nowo przyjrzeć się planetarnym strukturom władzy i wykluczeń, inaczej opisać relacje pomiędzy centrami i peryferiami, a także zrozumieć istniejące konflikty i współzależności geopolityczne. Gęsta sieć kabli łączy Stany Zjednoczone i Europę, pozwalając na intensywną i szybką wymianę informacji, przede wszystkim pomiędzy centrami finansowymi. Z kolei Afryka ma bardzo niewiele połączeń z Ameryką Południową. Jakie konsekwencje może mieć ograniczona wymiana pomiędzy krajami globalnego Południa przy równoczesnej intensywnej współpracy Północy i Zachodu? Na ile sieć kabli tworzy nowe ośrodki władzy, na ile odtwarza dawne zależności kolonialne, a na ile blokuje określone formy możliwych alternatywnych sojuszy? Odpowiedzi na te wszystkie pytania będą mieć fundamentalne znaczenie dla przyszłości planetarnych stosunków władzy.
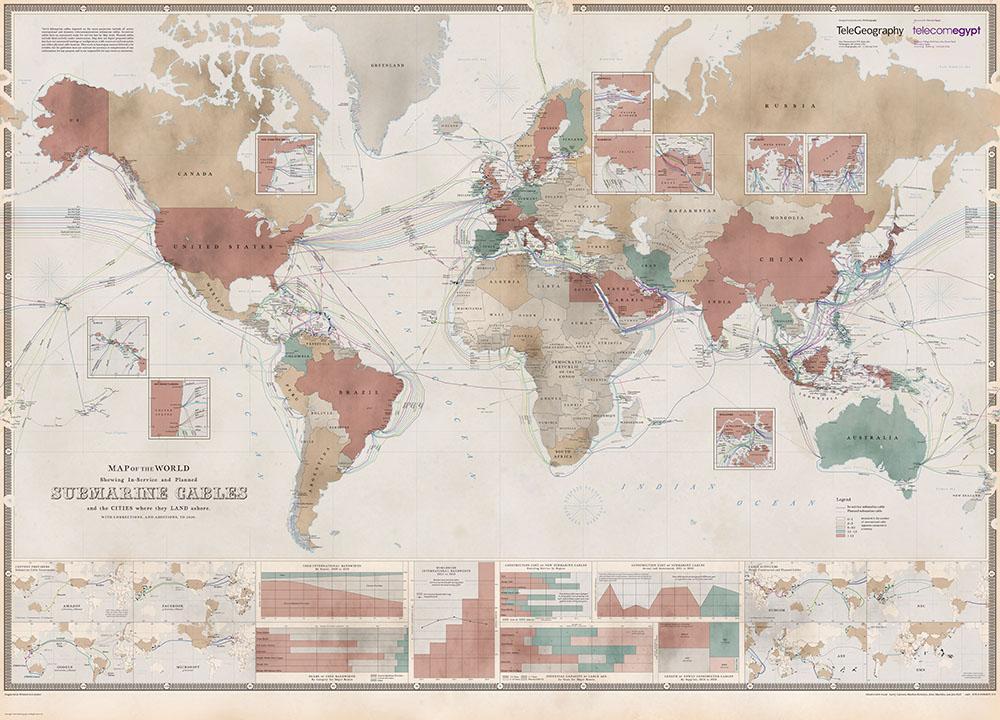
Mapa sieci kabli podmorskich. Źródło: J. Miller, The 2020 Cable Map Has Landed, „TeleGeography Blog”, 16.06.2020, https://blog.telegeography.com/2020-submarine-cable-map [dostęp: 27.03.2022].


Gdzieś tu – w spekulatywnie wyznaczonym miejscu – kablem Denmark–Poland 2 płynie internet. Fot. autora.

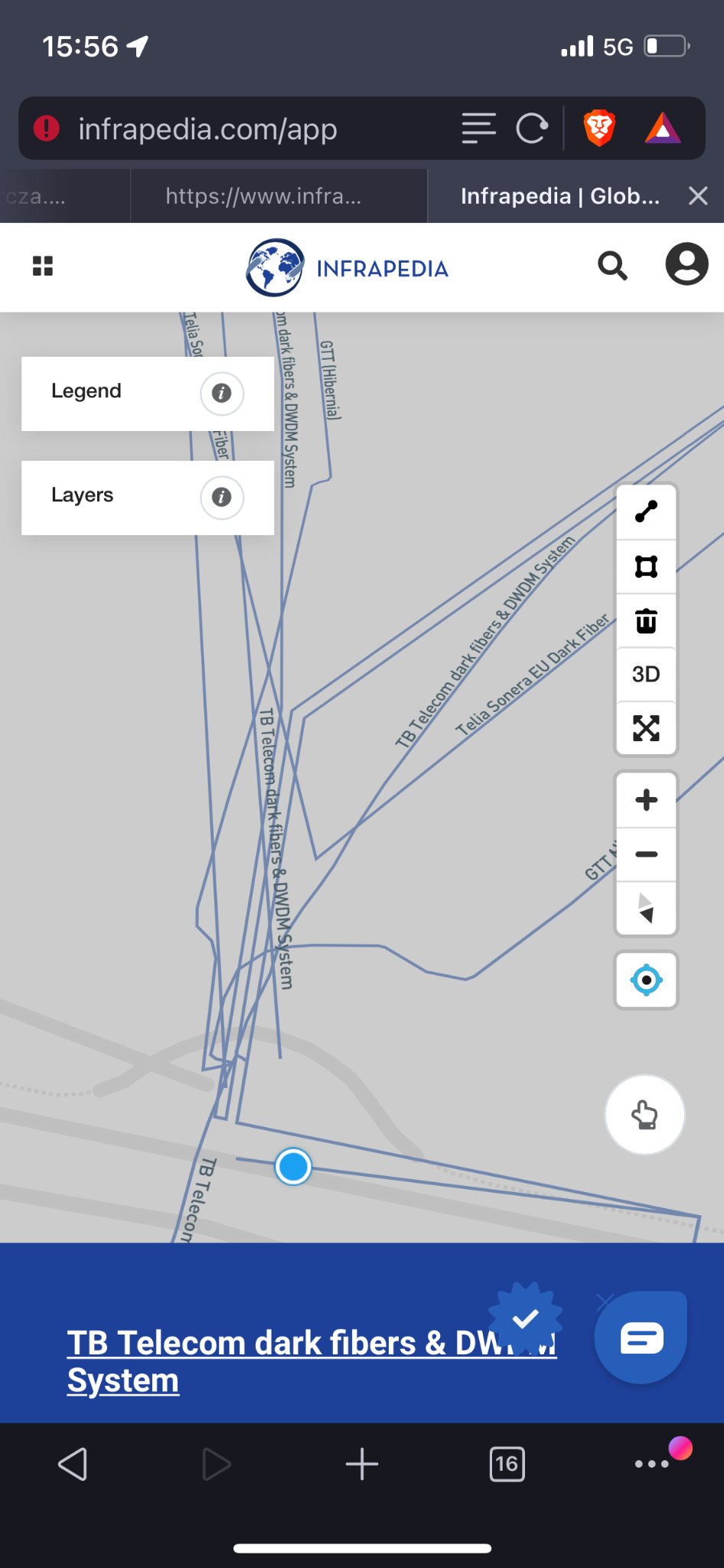
Miejsce, gdzie splata się ze sobą największa liczba kabli światłowodowych w Polsce. To one stanowią szkielet internetu. Przepływa przez nie większość danych przesyłanych w regionie. Fragment mapy: https://www.infrapedia.com/app [dostęp: 26.04.2022]. Fot. autora.
2. Na pustkowiach centrów przetwarzania danych
Podobnie jak kable i miejsca ich łączenia, centra danych umieszczone są w konkretnych lokalizacjach geograficznych i to właśnie lokalny kontekst – w wymiarze środowiskowym, politycznym, krajobrazowym, klimatycznym, ekonomicznym, społecznym czy geologicznym – splata się w nieoczywisty sposób z ich funkcjonalnością i charakterem zasobów, które się w nich znajdują. Niektóre centra danych, jak Kolos[4], położony za kołem podbiegunowym w Ballangen w Norwegii, korzystają z odnawialnych źródeł energii, w szczególności z energii wodnej. Istotne znaczenie mają tu uwarunkowania klimatyczne i możliwość wykorzystania mroźnego powietrza do chłodzenia serwerowni. Inne, jak Swiss Fort Knox[5], uznawane za najbezpieczniejsze centrum danych w Europie, znajdują się we wnętrzu gór. To centrum posiada wielopoziomową infrastrukturę z lądowiskami, pasem startowym na półkach górskich, a także z serwerowniami, agregatami, hotelem i zasobami wody ukrytymi we wnętrzu jednego z masywów Alp Szwajcarskich. Jeszcze inne znajdują się w dawnych bunkrach przeciwatomowych, 100 stóp pod ulicami Sztokholmu, jak Pionen firmy Bahnhof[6].
Internet ma swoją materialność, temperaturę i skład chemiczny. Skrzynki z serwerami, plątaniny kabli, systemy przeciwpożarowe, agregaty prądotwórcze, baterie, systemy chłodzenia – wszystkie te elementy infrastruktury internetu posiadają specyficzne faktury, zapach, giętkość, temperaturę, właściwości zarówno fizyczne, jak i zmysłowe. Ale internet ma też swój ciężar. Podczas wizyty w jednym z centrów danych w Gdańsku, oprowadzający nas po serwerowni współwłaściciel firmy zwrócił uwagę na wytrzymałość stropów jako ważny czynnik brany pod uwagę przy projektowaniu centrów danych lub poszukiwaniu dla nich istniejących budynków. W tym konkretnym przypadku strop musiał wytrzymać udźwig trzydziestu pięciu ton. Całkiem sporo jak na chmurę.
Centra danych – przez swoje systemy bezpieczeństwa, materialność, wygląd, lokalizację, architekturę i przypisane do nich narracje – wytwarzają wartość tego, co się w nich znajduje, czyli nadwyżki danych.
Centra danych zazwyczaj przedstawiane są jako miejsca położone na odludziu, dzikie i opuszczone[7]. Z zewnątrz widzimy je jako zatopione w dziewiczym krajobrazie, wśród wzgórz, pól i lasów. Ich wnętrza natomiast wyglądają jak sterylne, puste, odczłowieczone przestrzenie rodem z futurystycznej fantazji. A.R.E. Taylor twierdzi, że takie obrazy wspierają narrację, w której człowiek postrzegany jest jako zagrożenie dla bezpieczeństwa, automatyzacji i obiektywności danych[8]. Poprzez takie wizualne reprezentacje centra danych stają się przestrzeniami fantazji, wyobrażeniowymi, ideologicznymi i fantastycznymi obiektami.
Człowiek w przestrzeni centrum danych kojarzony jest ze źródłem błędu, a zatem stanowi zagrożenie dla niczym niezakłóconego działania systemu. Co więcej, na poziomie fantazmatycznym jego obecność blokowałaby urzeczywistnienie przyszłości jako w pełni zautomatyzowanej utopii. Przestrzeń nienaruszona i niezanieczyszczona ludzką obecnością ściśle współgra też z ideologią wiedzy tworzonej przez firmy zajmujące się analityką danych. Dane mają być obiektywne i niezależne od wpływu ludzkiej niedoskonałej natury, błędów, uprzedzeń, mają mówić same za siebie jako wynik idealnych procedur obliczeniowych, bezbłędnej kalkulacji. Estetyka znikania i nieobecności zasila wyobrażenia o wiedzy nienaruszonej przez ludzkie uprzedzenia i błędy, archaiczną niezborność i nieprzewidywalność człowieka.
To napięcie – pomiędzy fantazją na temat idealnej logiki komputacyjnej, w której każdy aspekt życia i świata zamieniony zostaje w dane, w model matematyczny, a wizją człowieka jako bytu nieokreślonego, nieredukowalnego do informacji, niedającego się pochwycić w logikę maszynową – wyznacza kluczowe wyzwanie, przed którym stoimy jako ludzie i które określi charakter naszej przyszłości. Czy człowieka można zredukować do ciągu zer i jedynek, zamienić w poddający się obliczeniom model statystyczny? Czy w związku z tym można, na podobieństwo praw naturalnych, przewidzieć jego działania, zachowania, myśli, nastroje i pragnienia?
Ten aspekt „naturalnego” charakteru danych podkreślany jest przez język, jakim o nich mówimy. Dane są pozyskiwane, zbierane i wydobywane, jak surowce lub zasoby naturalne, a nie wytwarzane przez systemy społeczno-technologiczne. Często mówieniu o nich towarzyszy bukoliczna terminologia: strumienie mediów, obliczeniowe chmury, jeziora danych. Ta związana z naturą wyobraźnia językowa tworzy ekologię mediów, w której dane stają się częścią praw rządzących wszechświatem – niezależnych od człowieka i istniejących obiektywnie.
Tymczasem to właśnie ludzkie uprzedzenia stanowią podstawę działania z pozoru tylko odczłowieczonych i automatycznych algorytmów[9].
3. Algorytmy i infrastruktura jako nowy wzór ukrytej władzy
Centra danych – jako część kompleksu przemysłowego – uzasadniają i stymulują wytwarzanie coraz większej ilości danych, ich nadwyżki, równocześnie nadając im wartość. W ten sposób powstaje istotna część nowego systemu kapitalizmu inwigilacji. Narracja o nasyceniu danymi, o ich wielości koniecznej do tworzenia nowej wiedzy i bardziej inteligentnego sposobu zarządzania różnymi obszarami świata, stanowi podstawowe uzasadnienie budowy nowych centrów danych. Równocześnie to właśnie w rezultacie powstawania tych obiektów występują okoliczności, w których „aż żal” nie wytwarzać nowych danych, nie produkować ich nadwyżki i nie gromadzić ich w tych miejscach, które oczekują na ich przyjęcie i przyciągają je do siebie (uwodzą).
Mél Hogan zwraca uwagę, że podobnie działał przemysłowy kompleks więzienny w Stanach Zjednoczonych[10]. Stworzona infrastruktura penitencjarna, zarządzana przez prywatne fundusze inwestycyjne typu REIT (real estate investment trust), stanowiła ramę i inspirację do późniejszych zmian prawnych oraz kryminalizacji imigracji. Pozwalała zarobić wtedy, kiedy był na nią popyt, a popyt był wtedy, kiedy wystarczająco duża liczba ciał – zazwyczaj czarnych i latynoskich ciał – uznawana była na podstawie tworzonego w tym celu prawa za kryminalistów, którzy powinni zostać osadzeni w więzieniu. W ten sposób publiczne środki przeznaczone na system sprawiedliwości trafiały ostatecznie do prywatnych kieszeni osób posiadających jednostki funduszy inwestycyjnych. Raz zbudowana infrastruktura więzienna wytwarzała system prawny, który uzasadniał jej istnienie i pozwalał na intensywniejszą akumulację kapitału.
Podobnie kompleks ponad 8 tysięcy centrów danych na świecie, połączonych światłowodową siecią kabli, tworzy materialne uzasadnienie produkcji coraz większej ilości danych. Są one z kolei wykorzystywane przez algorytmy sztucznej inteligencji do coraz sprawniejszej automatyzacji różnych obszarów życia i gospodarki. Systemy internetu rzeczy (Internet of things) poprzez komunikujące się ze sobą sieci czujników, które osadzone są w różnych materialnych obiektach i za ich pośrednictwem zbierają wszelkie możliwe dane, przesyłają do centrów danych i odbierają z nich „gęste” strumienie informacji.
To właśnie algorytmy stanowią – obok infrastruktury – drugą warstwę nowego szkieletu władzy w kapitalizmie inwigilacji. Potrzebują tych ogromnych zbiorów danych, ich nadwyżki, żeby uczyć się rozpoznawania nowych wzorców, doskonalić umiejętność „przewidywania” przyszłości i przekształcać same siebie w coraz doskonalsze systemy reguł i funkcji. Równocześnie założenia, na których się opierają, kryteria, na podstawie których dokonują klasyfikacji, i zasady, zgodnie z którymi działają, zazwyczaj są niejawne i ukryte. Nie wynika to tylko z braku kompetencji użytkowników, którzy nie znają języka programowania, ale też z prawa patentowego i tajemnicy handlowej. Ci, którzy tworzą algorytmy i nimi dysponują, często chcą, aby ich sposób działania był ukryty. Dzięki temu w większym stopniu mogą wpływać na wybory, zachowania i potrzeby użytkowników.
Algorytmy, podobnie jak infrastruktura, poddane są grze widzialności i niewidzialności. Te, które odpowiadają za uczenie maszynowe, coraz lepiej rozpoznają nasze skłonności, zachowania, potrzeby, pragnienia i nawyki. Potrafią odkryć rozmaite wzorce w różnych zbiorach danych – od nauk ścisłych i medycyny, przez ekonomię i procesy społeczno-polityczne, aż po techniki nadzoru, kontroli i inwigilacji. Nie tylko „zauważają” prawidłowości czy korelacje, lecz także tworzą hipotezy dotyczące ich rozwoju w przyszłości, ekstrapolując rozpoznane wzorce. Wiele naszych wyborów indywidualnych i zbiorowych – to, z kim rozmawiamy, jakie treści do nas docierają, gdzie podróżujemy, z kim budujemy relacje i w jaki sposób kochamy, czego słuchamy, jak projektujemy nasze wnętrza i komunikaty wizualne, którędy jeździmy do pracy, jak przewidujemy pogodę i katastrofy naturalne, wyniki wyborów i zagrożenia terrorystyczne – często jest rezultatem działania algorytmów.
4. Algorytmiczne uprzedzenia i normalizacja
Niestety świadomość, że tak się dzieje, nie sprawia, że wiemy, według jakich kryteriów, zasad i założeń działają algorytmy, jaka jest ich architektura, jakie ciągi komend i instrukcji składają się na ich strukturę, jakie procedury czy działania są przez nie wywoływane. Nie wiemy też, na jakich bazach danych były trenowane. Algorytmy bowiem uczą się rozpoznawania wzorców na przygotowanych specjalnie dla nich zbiorach, by potem mogły dokonywać klasyfikacji i generalizacji już poza tymi zestawami.
Tymczasem zbiory danych nie tylko mogą odtwarzać uprzedzenia, stereotypy i założenia, którymi kierują się różne grupy społeczne, reprodukując rozmaite historyczne ideologie. Mogą też być dobierane w taki sposób, by wspierać interes tych, którzy posiadają środki produkcji pozwalające na rozwój systemów sztucznej inteligencji. Zarówno same algorytmy, jak i bazy danych funkcjonują w sieci relacji władzy, nie są neutralne ani obiektywne.
Pierwszym etapem, na który wpływ ma człowiek, jest wybór bazy danych wykorzystywanej do trenowania danego algorytmu. Ta selekcja jest już oparta na założeniach na temat tego, co jest ważne, na co należy zwrócić uwagę, w jakim obszarze rzeczywistości algorytm ma poszukiwać cech i wzorów, a co może zostać zignorowane. Następnie ludzie dokonują „etykietowania” obiektów składających się na konkretną bazę i ich wstępnej kategoryzacji. Decydują, czy dany obiekt spełnia założone kryterium, i na tej podstawie go oznaczają, przypisując mu określoną kategorię. Na tych dwóch wstępnych etapach najczęściej dochodzi do reprodukcji stereotypów związanych z tym, co jest normą, a co anomalią, oraz uprzedzeń rasowych, genderowych czy etnicznych. Stare i konserwatywne taksonomie zostają wpisane w świat sztucznej inteligencji poprzez sposób organizacji „wkładu”, czyli zestawów danych, na których będą trenowane algorytmy uczenia maszynowego[11].
Tak przygotowane zestawy danych ze stworzoną przez ludzi taksonomią stają się polem treningowym algorytmów. Na tym etapie dochodzi zazwyczaj do wzmocnienia stereotypów i uprzedzeń zakodowanych w bazie i jej taksonomii. Algorytmy uczenia maszynowego dokonują przekształcenia danych w wielowymiarowy model statystyczny, który ma charakter przestrzeni wektorowej. Obiekty umieszczone zostają w kilkuwymiarowym układzie współrzędnych, w którym przypisane są im określone wartości liczbowe warunkujące ich lokalizację. Na przykład słowa czy wyrażenia języka naturalnego zaczynają funkcjonować jako zawieszone w różnych odległościach od siebie i w różnych relacjach związanych z częstotliwością występowania określonych korelacji czy związków między nimi. Słowo „lekarz” może występować częściej obok słowa „mężczyzna” niż „kobieta”, dlatego w przestrzeni wektorowej „lekarz” i „mężczyzna” znajdą się bliżej siebie. Jeśli z takiego modelu statystycznego w przyszłości będzie korzystać sztuczna inteligencja, której celem jest rekrutacja na stanowisko lekarza w szpitalu, prawdopodobnie częściej będzie wybierała kandydatów mężczyzn, ponieważ dostrzeże korelację pomiędzy tymi dwiema kategoriami.
Algorytmiczne tworzenie modelu statystycznego w wyniku treningu oznacza także likwidowanie wszelkich anomalii i spłaszczanie rzeczywistości do średniej. Jeśli pojawiają się wyniki, które odbiegają od jakiegoś wzorca czy trendu, zostają zignorowane i wchłonięte przez średnią. W ten sposób dochodzi do wzmocnienia normalizacji i stereotypów. Nietypowe wzory, prawdziwie innowacyjne pomysły czy nieszablonowe idee – wszystko to zostaje zignorowane przez algorytm uczenia maszynowego. Jeśli w bazie znajdują się elementy niepasujące do statystycznej normy, są one odrzucane. W ten sposób wielowymiarowość rzeczywistości zostaje zredukowana, a wszystko to, co nietypowe, odmienne, barwne, nieoczywiste, niestandardowe, odbiegające od normy, jest neutralizowane. Jak widać, algorytmy sztucznej inteligencji, choć wydają się technologią nadzwyczaj nowoczesną, w istocie często mają charakter niezwykle konserwatywny. Nie tylko reprodukują zastany porządek, status quo świata, ale także go wzmacniają.
Kolejnym wymiarem uproszczenia rzeczywistości jest koncentracja algorytmu uczenia maszynowego jedynie na wybranym zestawie cech. Oznacza to ograniczenie „rozdzielczości” świata do tego zestawu. Przez to sztuczna inteligencja może mylić obrazy obiektów w oczywisty sposób różnych i tak postrzeganych przez ludzkie oko – np. żółwia i karabinu – jeśli układ wybranych cech przypomina wzorzec, który algorytm nauczył się rozpoznawać jako charakterystyczny dla danej kategorii. Na przykład obraz żółwia algorytmy sztucznej inteligencji Google’a widziały jako karabin[12]. Z kolei identyczne dla ludzkiego oka obiekty mogą być postrzegane przez algorytm jako zupełnie inne, jeśli podmienimy cechy będące częścią wzorca.
Ta wiedza dotycząca działania algorytmu zazwyczaj jest nam niedostępna. Została zamknięta w czarnej skrzynce. Często nie znamy kodu źródłowego, baz danych, na których były trenowane algorytmy, ani innych danych wejściowych. Algorytmy są niewidzialnym szkieletem naszego świata, trochę jak niewidzialny labirynt czy niewidzialne sznurki poruszające naszym ciałem, naszymi afektami i procesami poznawczymi. Celem Biennale Warszawa 2022 „Seeing Stones and Spaces Beyond the Valley” jest wdarcie się do wnętrza czarnych skrzynek, wydobycie algorytmów z przestrzeni niewidzialności i pokazanie, w jaki sposób kształtują nas, materialność naszego świata i procesy społeczne, których jesteśmy częścią.
Vladan Joler i Matteo Pasquinelli zauważają, że narracje na temat tajemniczości algorytmów sztucznej inteligencji, niemożliwych do zrozumienia operacji odbywających się w sieciach neuronowych i retoryki nieprzeniknionych czarnych skrzynek to rodzaj mitologii stworzonej wokół sztucznej inteligencji po to, żeby przedstawiać ją jako niemożliwą do poznania i niepodlegającą politycznej kontroli[13]. Zależy nam na przełamaniu tego impasu, ujawnieniu politycznych kontekstów technologii i wskazaniu, że kierunek ich rozwoju nie jest zdeterminowany przez niejasne i tajemne siły, ale zależy od naszej sprawczości jako ludzi i od decyzji politycznych, które podejmujemy. Dlatego tak ważna jest debata na temat tego, jakich technologii chcemy, a jakich nie chcemy; jaka przyszłość jest nam bliska i jakimi środkami moglibyśmy ją osiągnąć. Jednym z ważnych celów programu jest odblokowanie naszej wyobraźni społeczno-politycznej związanej z przyszłością technologii – pokazanie, że możliwe jest przejście od krytycznej analizy kapitalizmu inwigilacji do myślenia o technologiach demokratycznych czy wspólnotowych.
Twórcza, sprawcza i polityczna praca nad projektowaniem przyszłości jest o tyle ważna, że algorytmy sztucznej inteligencji – stworzone w celu wydobywania (ekstrakcji) i klasyfikacji naszych najbardziej intymnych danych – tworzą modele statystyczne przyszłości wyłącznie w formie ekstrapolacji przeszłych wzorców. Konsekwencją tego jest brak możliwości odkrycia przez nie czegoś naprawdę nowego, idei nigdy wcześniej niepomyślanej i nieutrwalonej. Uczenie maszynowe nie jest w stanie wyjść poza odtwarzanie przeszłości. W najlepszym wypadku są to wariacje na temat wzorców z przeszłości, ich rekonfigurowanie, mieszanie i przetwarzanie. Algorytmy uczenia maszynowego tworzą przyszłość w postaci mitologicznego obrazu – powtarzanego i odtwarzanego – przez co stają się maszyną mitologiczną. W związku z tym często odtwarzają istniejące klasyfikacje, dychotomie, uprzedzenia i stereotypy genderowe, klasowe, rasowe i seksualne. Jeśli algorytmy uczyły się klasyfikacji na podstawie zestawów danych opartych na charakterystycznych dla kultury Zachodu przekonaniach i systemie wartości, to będą je reprodukowały, podejmując z pozoru tylko obiektywne i neutralne, automatyczne decyzje. Microsoft w 2016 roku stworzył bota, który miał się uczyć z twitterowych wpisów użytkowników. W ciągu dwudziestu czterech godzin stał się on zautomatyzowanym rasistowsko-seksistowskim dyskursem nienawiści, odtwarzając jedynie wzorce rozpoznane w komunikacji „ludzkich” agentów[14]. Z kolei niejawny algorytm „Elo score” Tindera, który mierzy poziom „pożądaniowości” (desirability) użytkowników, utrwala seksistowskie praktyki oceniania innych osób jako obiektów seksualnych i przyznawania im ocen liczbowych. Podobnie problematyczne są eksperymenty ze sztuczną inteligencją, która na podstawie rysów twarzy jest w stanie przewidzieć orientację seksualną danej osoby. To tylko wybrane przykłady[15] algorytmów utrwalających binarne podziały i odtwarzających istniejące ideologie. Regresywno-konserwatywny charakter z pozoru progresywnych technologii dostrzeżemy wyraźnie, jeśli uświadomimy sobie, że reprodukowane przez algorytmy kategorie społeczne były przez wiele lat podważane i dekonstruowane nie tylko przez autorki i autorów myśli krytycznej, ale też w ramach rozmaitych prorównościowych polityk publicznych. Wprowadzana bez rozwagi automatyzacja zaprzepaścić może wcześniejsze krytyczne wysiłki. Póki co wydaje się, że przeważają raczej uogólnienia i odtwarzanie starych podziałów społecznych i relacji władzy.
Algorytmy uczenia maszynowego są ściśle powiązane z przemysłowym kompleksem centrów danych, który uzasadnia wytwarzanie nadwyżki, jak pisze o tym Mél Hogan[16]. Nadwyżka danych potrzebna jest bowiem do doskonalenia się algorytmów. Dzięki niej mają pożywkę do rozwoju, odnajdywania nowych wzorców w świecie i potencjalnie – do przejmowania od ludzi kolejnych zadań i czynności. Algorytmy odczytują nasze emocje na podstawie wyrazu twarzy i podsłuchują nasze rozmowy, nie tylko przetwarzając znaczenia słów, które wypowiadamy, ale też analizując ton głosu, jego brzmienie, subtelne zmiany głośności i nasilenia oraz próbując „zrozumieć” szeroki kontekst naszych wypowiedzi. Dzięki powiązaniu ze sobą wielu tysięcy punktów danych z różnych momentów życia powstać może nie tylko zadziwiająco dokładny profil psychologiczny danej osoby, obejmujący wiele niuansów niemożliwych do uchwycenia przez percepcję najbardziej nawet wnikliwego psychoterapeuty, ale też niezwykle szczegółowa rekonstrukcja scenariusza życia[17]. Samochody autonomiczne z kolei uczone są podejmowania etycznych decyzji na podstawie programowalnych systemów „wartości” możliwych do zastosowania w hipotetycznych sytuacjach na drodze. Systemy internetu rzeczy (Internet of things) – w ramach którego materialne obiekty naszpikowane czujnikami „rozmawiają” ze sobą – przekazują sobie informacje, integrują dane, tworzą nowe korelacje, podsłuchują nas i gromadzą wiedzę o zależnościach pomiędzy naszym nastrojem, zachowaniem i reakcjami naszego organizmu, zbieranymi przez rozmaite urządzenia ubieralne, często powiązane z aplikacjami fitnessowo-sportowymi lub wspierającymi nasze zdrowie. Algorytmy potrafią też diagnozować nowotwory na podstawie zdjęć USG, niekiedy lepiej niż człowiek, widząc delikatne zmiany mogące być początkiem rozwoju wzorca obrazu nowotworu.
Sztuczna inteligencja może być jednak wykorzystana również do profilowania rasowego i wprost wspierać autorytarne reżimy w systemowej opresji i przemocy. Pierwszym ujawnionym przykładem algorytmicznego profilowania rasowego był system chińskiej firmy CloudWalk[18]. Wytrenowany na twarzach Ujgurów i Tybetańczyków algorytm nauczył się rozpoznawać osoby pochodzące z tych grup narodowościowych. Następnie został połączony z systemami monitoringu miejskiego opartymi na kamerach CCTV. Pozwoliło to na stworzenie baz danych wejść Ujgurów do danej dzielnicy i wyjść z niej, śledzenie ich trasy przemieszczania się po mieście i częstotliwości przekraczania danych punktów w przestrzeni. Na tej podstawie określono mapy wzorców ruchu danych mniejszości w przestrzeni. Co więcej, jeśli w konkretnej dzielnicy pojawiała się odbiegająca od standardu liczba osób z „wrażliwych” grup, system automatycznie informował służby o zagrożeniu.
Ten jawnie rasistowski system inwigilacji państwowej mógłby zostać połączony z analizą zbieranych przez Chiny danych genetycznych o grupach „wrażliwych”. DNA wydaje się kolejnym obszarem, w który powoli wwierca się świder wydobycia danych i ich algorytmicznej analizy. Już nie tylko uczucia, choroby, problemy psychiczne, nałogi, intymne relacje, życie seksualne, neurozy i skłonności mogą stanowić źródło danych wykorzystywanych do tworzenia naszych profili. Mogą one zostać powiązane z wnikliwą analizą indywidualnych sekwencji DNA przez sztuczną inteligencję i tworzeniem najbardziej nieprawdopodobnych korelacji łączących nasze geny i zachowania. Nietrudno wyobrazić sobie konsekwencje tak daleko idącej inwigilacji i utowarowienia naszych unikalnych kodów życia. Na giełdach danych firmy lub partie polityczne mogłyby kupić paczki danych w ramach kategorii łączących charakterystyki behawioralne z określonymi sekwencjami kodu genetycznego.
Podobnie problematyczną praktyką jest testowanie nowych systemów sztucznej inteligencji w obszarze migracji, procedur uchodźczych i bezpośrednio na granicach. Osoby uchodźcze, osoby bezpaństwowe, osoby w ruchu, osoby pozbawione dokumentów – często uciekające przed wojną i prześladowaniami lub z miejsc o ekosystemach zniszczonych na skutek zmian klimatycznych – są w szczególny sposób podatne na eksploatację. Nie chodzi tu tylko o handel ludźmi czy różne formy wyzysku pracowniczego, ale też o sytuację, w której osoby te pozbawione są praw chroniących obywateli m.in. przed naruszeniami prywatności związanymi z wydobyciem, przechowywaniem i przetwarzaniem danych.
Co więcej, ze względu na liminalny status osób uchodźczych i łatwość zdefiniowania ich jako „wyjętych spod prawa” służby państwowe ramię w ramię z prywatnym biznesem technologicznym wykorzystują tę sytuację do testowania problematycznych technologii inwigilacji, automatycznych systemów podejmowania decyzji i wydobycia danych. Nie tylko sprawdzają ślad cyfrowy osób uchodźczych na podstawie danych z ich telefonów, ale też jak Palantir – firma zajmująca się zaawansowaną analityką danych – profilują te osoby, integrując dane z wielu źródeł. Wykorzystywane to było m.in. w trakcie prezydentury Donalda Trumpa do przeprowadzania deportacji i rozdzielania rodzin migranckich przez amerykańską agencję Immigration and Customs Enforcement[19].
Na granicach testowane są też automatyczne wykrywacze kłamstw, które na podstawie wyrazu twarzy i brzmienia głosu w czasie odpowiedzi na coraz bardziej skomplikowane pytania starają się przeprowadzić analizę prawdomówności i wytypować podejrzane osoby. Czy jednak algorytm, wytrenowany na zestawach danych zakorzenionych w określonym kontekście, uwzględni różnice kulturowe w ekspresji? Czy będzie w stanie odróżnić niespójności w odpowiedziach wywołane uszkodzeniami procesów poznawczych na skutek traumy wojennej od tych, które są wynikiem oszustwa? Jeśli osoba uchodźcza chciałaby się odwołać od algorytmicznie podjętej decyzji, to kto byłby odpowiedzialny? Osoba projektująca system, programista, urzędnik imigracyjny, a może sam algorytm[20]?
5. Kapitalizm inwigilacji i cyberwojna
Jak pisze Svitlana Matviyenko, to właśnie użytkownicy stają się swoistym mięsem armatnim podczas cyberwojny. Często funkcjonują jako doskonałe, automatyczne przekaźniki transmisji informacji. Uprzedmiotowieni, traktowani jak zasób i produkt zarazem, jak źródło danych i matematycznie wyprofilowana behawioralna broń, wyzyskiwani są za sprawą własnego człowieczeństwa: lęków, niepokojów, pragnień, słabości, wrażliwości, podatności, nałogów, wiedzy, nawyków, zachowań, przekonań. Wszystkie te najbardziej ludzkie, emocjonalne, afektywne i poznawcze właściwości zamieniane są na układy danych[21]. Każdy człowiek staje się w tym procesie pewnym statystycznym układem cech i właściwości, matematycznym modelem czy wzorcem, z którego określonością i parametryzacją mogą następnie pracować algorytmy sztucznej inteligencji. To one przewidują zachowania i układają je w korelacje. Dzięki nim staje się wiadome, co zrobić, aby określony człowiek – jako statystyczny układ cech – zachował się w określony sposób. W ten sposób – na zasadzie behawioralnej manipulacji – można sterować zachowaniami, poglądami czy nałogami poszczególnych osób i całych populacji.
Tak funkcjonują cyfrowe monopole big data oraz rozmaite agencje państwowe, które splatają się ze sobą w powiązaniach kapitałowych i w relacjach władzy. Ten nowy paradygmat Shoshana Zuboff nazwała kapitalizmem inwigilacji. Wśród wielu jego określeń znalazły się m.in. takie: „nowy porządek ekonomiczny, który uznaje ludzkie doświadczenie za darmowy surowiec do ukrytych handlowych praktyk wydobycia, prognozowania i sprzedaży” czy „pasożytnicza logika ekonomiczna, w której wytwarzanie towarów i usług jest podporządkowane nowej globalnej architekturze modyfikacji behawioralnych”[22]. To samo ludzkie doświadczenie, w jego złożoności i nieokreśloności, przechwytywane jest przez rozmaite sensory zbierające dane, a następnie spłaszczane do statystycznej średniej. Ostatecznie wytwarzany jest model, którym można zarządzać i manipulować, którego stany i zachowania można przewidywać na zasadzie predykcji – ekstrapolacji w przyszłość tendencji i wzorców dostrzeżonych przez algorytm w przeszłości – i który można sprzedawać jako produkt w opatrzonych kategoriami paczkach danych (np. osoby myślące o śmierci, osoby, które mają problem z własnym ciałem, kobiety w ciąży, osoby z tendencjami do uzależnień, osoby mające skłonność do ryzyka, osoby przepełnione lękiem o rodzinę, osoby chore na depresję).
Jeśli algorytm wie o tobie więcej, niż ty sam wiesz o sobie, utwierdzać cię może w przekonaniach i nawykach korzystnych dla tej grupy albo firmy, która go stworzyła i czerpie z niego zyski: finansowe, propagandowe lub militarne. Ten sam sposób działania, polegający na zamianie w dane ludzkich zachowań i właściwości, a także całego kontekstu środowiskowego, społecznego, relacyjnego i materialnego, służyć może zarówno rynkowej kapitalizacji, jak i władzy państwowej. Może też być zasobem i narzędziem wykorzystywanym w cyberwojnie. Jak twierdzi Matviyenko, „cyberwojna jest wojną kapitalistyczną”[23]. Dodaje, że to właśnie poddany algorytmicznej analizie zestaw danych o ludzkich emocjach, pragnieniach, zachowaniach i wszelkich podatnościach służy celom cyberwojny poprzez wzmacnianie polaryzacji użytkowników sieci oraz reprodukcję antagonizmów i związanych z nimi toksycznych relacji w ramach „echokomnat” i rozmaitych baniek informacyjno-światopoglądowych[24].
Polaryzacja i antagonizmy sprawiają, że użytkownicy produkują jeszcze więcej nowych danych. To właśnie one mobilizują ukryte w nas intymne fabryki afektywno-behawioralne do wytwarzania nowych danych – w odpowiedzi na prowokacje, w aktach oburzenia, w potrzebie wsparcia „swoich”, w głębokim pragnieniu zamanifestowania niezgody. Facebookowe potyczki, starcia, burze i wojny w istocie służą do tego, żeby zbudować fałszywy antagonizm opierający się na algorytmicznie sprowokowanym konflikcie. Faktycznie skrywa on inny podział na tych, którzy czerpią zyski z danych wytworzonych w „ideologicznych agonach”, i tych, których „lęki i pragnienia poddane są instrumentalizacji przez wojnę, użytkowników platform”[25]. Z takiego rozpoznania Matviyenko wyciąga wniosek, że platformy kapitalistyczne wspierają polityzację i militaryzację komunikacji.
Co więcej, każda kolejna forma oporu, każdy kolejny protest, każda kolejna strategia czy taktyka niezgody analizowane i rozpoznawane są przez algorytmy sztucznej inteligencji, które uczą się ich wzorów, dynamik i technik, by w przyszłości szybciej je dostrzegać i na nie reagować, osłabiając ich skuteczność i potencjał. Zauważmy, że tak właśnie działa autorytarna władza. Kontekst cyberwojny, widziany również w perspektywie wojny w Ukrainie, ujawnia splątanie dwóch autorytarnych technik: z jednej strony uciszania użytkowników, zabierania im głosu i narzędzi komunikacji w zgodzie z duchem totalitarnym; z drugiej neoliberalnej metody uwodzenia wolnością i inspirowania do tego, aby mówić w sposób „wolny”, by przechwytywać myśli i uczucia tak wytworzone w zarzucone na nie siatki kwantyfikacji i zamiany tej „wolnej ekspresji” w utowarowiony zestaw danych. Obie taktyki – uciszania w jednym miejscu, a inspirowania do mówienia (krzyczenia, agonu, sporu, gniewu…) w innym – mają kluczowe znaczenie w dialektyce wojny w Ukrainie.
6. Ruch technologii niezaangażowanych i centrum danych w ogrodzie
Algorytmy uczenia maszynowego opierają się na uchwyceniu korelacji pomiędzy zjawiskami, nie potrafią jednak zrozumieć przyczynowości. Jednym z podstawowych błędów takiej perspektywy jest przekształcanie korelacji w przyczynowość. Jeśli np. osoby, które regularnie podróżują, częściej wchodzą w nowe związki, nie oznacza to, że istnieje związek przyczynowo-skutkowy pomiędzy podróżowaniem a trwałością relacji miłosnych czy gotowością do inicjowania nowych. Wydobywając rozmaite dane, uczenie maszynowe może ustanowić w zasadzie dowolny, arbitralny rodzaj korelacji, a następnie przedstawić go jako związek przyczynowo-skutkowy[26]. Algorytmy obsesyjnie „dopasowują krzywą”, wytwarzając rozmaite korelacje bez podawania wyjaśnień. Dlatego sztuczna inteligencja nie ma głębszego wglądu w pewne zjawiska, nie rozumie ich i nie może wyjaśnić. Uznawanie korelacji za związki przyczynowo-skutkowe staje się niebezpieczne wtedy, kiedy wchodzimy w obszar przewidywania przyszłości, czyli algorytmicznej predykcji. Skoro algorytmy sztucznej inteligencji stosowane są w procedurach granicznych, w kryminalistyce i do podejmowania decyzji w sytuacji wojennej, może się okazać, że działania wyprzedzające, które stanowią odpowiedź na rozmaite predykcje, są całkowicie nietrafione i fałszywie tworzą podejrzanych, kryminalizują niewinnych czy wskazują błędne cele ataku.
Równie ryzykowne jest zawierzenie naszej przyszłości sztucznej inteligencji, która tylko odtwarza przeszłe wzorce, nie może wykryć tego, co nowe, niweluje innowacje, a dodatkowo opiera swoje wizje przyszłości na korelacji zjawisk z przeszłości. W takiej sytuacji niezwykle ważne staje się odwołanie do kreatywności i sprawczości ludzkiej. To człowiek może wyjaśnić relacje przyczynowo-skutkowe między zjawiskami i stworzyć plan, w którym, przechodząc od punktu do punktu, będziemy zmierzać do realizacji przyszłości, jakiej naprawdę chcemy. To ludzka wyobraźnia może wytworzyć obrazy czy wizje wcześniej niewyobrażone, a ludzka myśl – idee wcześniej niepomyślane. Kiedy używamy w tytule naszej wystawy wyrażenia „poza doliną”, zależy nam na wyjściu poza wyobrażeniowe ramy stworzone przez firmy, dyskurs i praktyki Doliny Krzemowej, ale też na tym, by bezustannie pracować z poszerzaniem granic własnej wyobraźni, rozciąganiem jej, twórczym kwestionowaniem oczywistości – nie tylko w celu odsłaniania niesprawiedliwości i relacji władzy, ale też po to, by tworzyć pole dla potencjalności, twórczych praktyk i idei. By wychodzić poza dolinę naszej wyobraźni, sprawdzać i testować to, co wydaje się nieprawdopodobne, nieosiągalne, alternatywne, niezgodne z istniejącym paradygmatem, a co pozwala myśleć o lepszym świecie, poza mrokiem, poza apokaliptyczno-katastroficzną doliną.
Takie praktyki, prototypy, idee, spekulacje i wyobrażenia znajdziecie na naszej wystawie i w naszym programie publicznym. Chciałbym wskazać dwie alternatywy, które odpowiadają na wyzwania związane z kompleksem przemysłowym centrów danych oraz tym, co Nick Couldry i Ulises Ali Mejias nazywają kolonializmem danych.
Wyobraźmy sobie, że zamiast centrów danych, w których przechowywane są informacje zapisane w postaci kodu binarnego, zaczniemy skutecznie i efektywnie kodować dane – teksty, filmy, fotografie, dźwięki – w DNA roślin lub innych organizmów[27]. W DNA zakodowane zostały już utwory Milesa Davisa, mowa Martina Luthera Kinga Jr. I Have a Dream, fotografie, sonety Szekspira, wirus komputerowy i wiele innych informacji[28]. Zamiast ponad 8 tysięcy centrów danych, zużywających bezcenne zasoby wody i generujących duży ślad węglowy, moglibyśmy tworzyć ogrody-archiwa, w których przechowywane byłyby nasze prywatne dane, i palmiarnie danych, w których gromadzona byłaby wiedza kluczowa dla ludzkości. Jeden gram DNA pozwala na zakodowanie około miliona gigabajtów danych. Oznacza to, jak pisze Mél Hogan, że wszystkie dane, które aktualnie wytwarzamy na całym świecie, zmieściłyby się w pojemniku wielkości bagażnika samochodowego[29]. Co więcej, zamrożone DNA jest bardzo trwałe i może być przechowywane w takim stanie przez 2 miliony lat. Tę możliwość eksploruje pokazywana na wystawie praca kolektywu Grow Your Own Cloud Data Garden.
O ile przechowywanie danych w organizmach roślinnych stanowi odpowiedź na wyzwania związane z materialną infrastrukturą internetu, o tyle Couldry i Mejias proponują, by na zjawisko kolonializmu danych odpowiedzieć strategiami i taktykami wykorzystywanymi w ramach ruchów dekolonizacyjnych. Postrzegają oni ekstrakcję (wydobycie) wartości z ludzkiego życia za pośrednictwem danych jako praktykę wpisaną w pięćsetletnią historię kolonializmu[30]. Sytuują ją w perspektywie długiego trwania (longue durée) i pokazują, w jaki sposób akumulacja przez wywłaszczenie (pojęcie zaproponowane przez Davida Harveya) dotyczyć może zarówno grabieży ziemi, zawłaszczenia zasobów naturalnych, ziemi i pracy, jak i danych. Zawłaszczenie danych – wydobytych z życia ludzkiego – w tym podobne jest do zawłaszczenia ziemi, że w obu sytuacjach ktoś (Google lub konkwistadorzy) rości sobie prawo do rzekomo niczyich zasobów – ziemi (w społecznościach bez prawa własności) lub danych (m.in. śladu cyfrowego, który pozostał po naszych aktywnościach w sieci). Dane, podobnie jak ziemia, przedstawiane są jako niczyje, „leżące odłogiem”, możliwe do przejęcia wraz z podpisaniem przez użytkownika deklaracji zrzeczenia się własności (o ile wytwarzamy lub przechowujemy je w ramach usług platform cyfrowych).
Dla Couldry’ego i Mejiasa ekstraktywizm i kolonializm danych stanowią zjawisko pierwotne wobec kapitalizmu – umożliwiający kolejne fazy jego rozwoju nowy etap kolonializmu. Inspirują oni do krytycznego przyjrzenia się wymówkom i usprawiedliwieniom, które w okresie kolonializmu miały uzasadniać masową ekstrakcję surowców naturalnych i – analogicznie – pojawiają się dzisiaj w kontekście ekstrakcji danych. Są to: racjonalność, progres, porządek, nauka, nowoczesność, zbawienie[31]. Towarzyszą im przekonania, prezentowane w debacie jako oczywiste i bezdyskusyjne, że bez gromadzenia danych świat nie będzie mógł się rozwijać, nie będzie rozumiany, sensownie zarządzany, a w końcu – np. w kontekście katastrofy klimatycznej – nie zostanie ocalony[32].
Odpowiedzią na takie rozpoznanie jest praca wyobraźni w skali globalnej. Wszystkie strategie dekolonizacyjne były zawsze aktami wyobraźni, dlatego również teraz tak ważne jest stworzenie alternatywnych wyobrażeń związanych z danymi i technologiami. Couldry i Mejias proponują, by powołać ruch technologii niezaangażowanych (na wzór ruchu państw niezaangażowanych), który m.in. bojkotowałby technologie ekstraktywistyczne i stosował alternatywne technologie, prowadziłby do niekupowania lub nieakceptowania „darmowych” produktów monopoli cyfrowych, odzyskiwałby dane (i produkty z nich powstałe) w imieniu tych, którzy je stworzyli, wprowadzałby podatki i sankcje wobec Big Techów, by w ten sposób naprawić szkody wyrządzone przez ich technologie, pracowałby nad nową wyobraźnią i nowymi formami społeczności bez technologii ekstraktywistycznych i związanych z nimi poważnych kosztów oraz tworzyłby solidarność, która łączyłaby w skali globalnej „niezaangażowane jednostki i społeczności na całym świecie siłą zbiorowej wyobraźni i na drodze wspólnego działania”[33].
Te pomysły stanowić mogą inspirujący punkt wyjścia do własnych eksperymentów z alternatywami technologicznymi: do tworzenia nowych idei, prototypów, organizacji i kolektywów zdolnych budować nowy – demokratyczny, sprawiedliwy i równiejszy – świat. Jedno wiemy na pewno – w tym świecie technologie kształtować będą większość zjawisk politycznych, egzystencjalnych, społecznych, ekologicznych i ekonomicznych. Od nas zależy, w jaki sposób go urządzimy.
- J. Marías, Twoja twarz jutro, tłum. E. Zaleska, Wydawnictwo Sonia Draga, Katowice 2016, s. 11. ↑
- Zob. L. Drulhe, Critical Atlas of Internet. Spatial analysis as a tool for socio-political purposes, https://louisedrulhe.fr/internet-atlas/ [dostęp: 20.04.2022]. ↑
- „People think that data is in the cloud, but it’s not. It’s in the ocean.”, „The New York Times”, https://www.nytimes.com/interactive/2019/03/10/technology/internet-cables-oceans.html [dostęp: 20.04.2022]. ↑
- „Kolos. Powering the Future”, https://kolos.com/ [dostęp: 20.04.2022]. ↑
- Swiss Fort Knox. Europe’s most secure datacenter, „Mount10”, https://www.mount10.ch/en/mount10/swiss-fort-knox [dostęp: 20.04.2022]. ↑
- H. Menear, Pionen: Inside the world’s most secure data centre, „Data Centre Magazine”, 8.07.2020, https://datacentremagazine.com/data-centres/pionen-inside-worlds-most-secure-data-centre [dostęp: 20.04.2022]. ↑
- A.R.E. Taylor, The Data Center as Technological Wilderness, „Culture Machine” 2019, Vol. 18, https://culturemachine.net/vol-18-the-nature-of-data-centers/data-center-as-techno-wilderness/ [dostęp: 7.04.2022]. ↑
- Tamże. ↑
- Tamże. ↑
- M. Hogan, The Data Center Industrial Complex, https://www.academia.edu/39043972/The_Data_Center_Industrial_Complex_forthcoming_2021_ [dostęp: 7.04.2022]. ↑
- V. Joler, M. Pasquinelli, The Nooscope Manifested. AI as Instrument of Knowledge Extractivism, 2020, https://nooscope.ai/ [dostęp: 9.04.2022]. Polska wersja językowa: ciż, Nooskop ujawniony – manifest. Sztuczna inteligencja jako narzędzie ekstraktywizmu wiedzy, 2020, tłum. K. Kulesza, C. Stępkowski, A. Zgud, https://nooskop.mvu.pl/ [dostęp: 9.04.2022]. ↑
- J. Vincent, Google’s AI thinks this turtle looks like a gun, which is a problem, „The Verge”, 2.11.2017, https://www.theverge.com/2017/11/2/16597276/google-ai-image-attacks-adversarial-turtle-rifle-3d-printed [dostęp: 9.04.2022]. ↑
- V. Joler, M. Pasquinelli, dz. cyt. ↑
- J. Vincent, Twitter taught Microsoft’s AI chatbot to be a racist asshole in less than a day, „The Verge”, 24.03.2016, https://www.theverge.com/2016/3/24/11297050/tay-microsoft-chatbot-racist [dostęp: 10.04.2022]. ↑
- Z inspiracji: M. Hogan, dz. cyt. ↑
- Tamże. ↑
- „Made to Measure”, https://madetomeasure.online/de/ [dostęp: 20.04.2022]. ↑
- P. Mozur, One Month, 500,000 Face Scans: How China Is Using A.I. to Profile a Minority, „The New York Times”, 14.04.2019, https://www.nytimes.com/2019/04/14/technology/china-surveillance-artificial-intelligence-racial-profiling.html [dostęp: 9.04.2022]. ↑
- S. Woodman, Palantir Provides the Engine for Donald Trump’s Deportation Machine, „The Intercept”, 2.03.2017, https://theintercept.com/2017/03/02/palantir-provides-the-engine-for-donald-trumps-deportation-machine/ [dostęp: 10.04.2022]. ↑
- P. Molnar, Technological Testing Grounds. Migration Management Experiments and Reflections from the Ground Up, EDRI, Refugee Law Lab, 2020, https://edri.org/wp-content/uploads/2020/11/Technological-Testing-Grounds.pdf [dostęp: 10.04.2022]. ↑
- Reconsidering Cyberwar: an interview with Svitlana Matviyenko, https://machinic.info/Matviyenko [dostęp: 5.04.2022]. ↑
- S. Zuboff, Wiek kapitalizmu inwigilacji. Walka o przyszłość ludzkości na nowej granicy władzy, tłum. A. Unterschuetz, Zysk i S-ka Wydawnictwo, Poznań 2020, s. 9. ↑
- Reconsidering…, tłum. własne. ↑
- Zob. tamże. ↑
- Tamże. ↑
- V. Joler, M. Pasquinelli, dz. cyt. ↑
- Zob.: J. Davis, S. Khan, K. Cromer, G.M. Church, Multiplex, cascading DNA-encoding for making angels [w:] A New Digital Deal. How the Digital World Could Work, ed. M. Jandl, G. Stocker, Ars Electronica 2021, Festival for Art, Technology & Society, Hatje Cantz, Berlin 2021, s. 148–155.W jaki sposób można jednak zakodować informacje w DNA roślin? Komputery czytają kod binarny, czyli informacje zapisane w postaci zer i jedynek. Aby zapisać ciągi zer i jedynek w DNA, zacząć musimy od przypisania określonych wartości liczbowych jego poszczególnym składowym. Kod genetyczny składa się z czterech podstawowych nukleotydów – adeniny, cytozyny, guaniny i tyminy (ACGT) – które tworząc trzyelementowe struktury nazywane kodonami (np. TGT, TCG, AAG, GTA), kodują jeden z dwudziestu aminokwasów. Niektóre aminokwasy mogą być kodowane przez różne kodony, np. lizyna (Lys) kodowana jest przez ciągi AAA lub AAG. Ciąg kodonów określa, jakie sekwencje aminokwasów złożą się następnie na białka charakterystyczne dla danego organizmu. Cztery nukleotydy mogą zostać ułożone w sześćdziesiąt cztery różne trzyelementowe kombinacje kodonów.Kodowanie informacji zapisanych w kodzie binarnym zacząć możemy od przypisania poszczególnym nukleotydom wartości liczbowych zgodnie z ich masą cząsteczkową: C = 0, T = 01, A = 10, G = 11 (od najlżejszej do najcięższej). W ten sposób np. sekwencja 11011000 odpowiadać będzie ciągowi GTACC nukleotydów. Podobnie wartości liczbowe przypisać możemy każdemu z sześćdziesięciu czterech kodonów kodujących poszczególne aminokwasy, a także każdemu z dwudziestu aminokwasów. Do cysteiny (Cys) – która kodowana jest przez kodony TGT i TGC – przypisana zostaje wartość 1101, do alaniny (Ala) – kodowanej przez GCT, GCC, GCA, GCG – 1011, do glutaminy (Gln) – kodowanej przez CAA, CAG – 100. Analogicznie do pozostałych siedemnastu aminokwasów przypisane zostają inne możliwe ciągi zer i jedynek: 0000, 00, 1000, 1010, 10, 101… Dzięki takiemu systemowi możliwe jest redundantne zakodowanie każdej informacji, która wcześniej zapisana została w kodzie binarnym. ↑
- Zob. M. Hogan, DNA [w:] Uncertain Archives. Critical Keywords for Big Data, ed. N. Thylstrup, D. Agostinho, A. Ring, C. D’Ignazio, K. Veel, The MIT Press, Cambridge 2021, s. 171–178. ↑
- Tamże. ↑
- N. Couldry, U.A. Mejias, The decolonial turn in data and technology research: what is at stake and where is it heading?, „Information, Communication & Society” 2021, https://www.tandfonline.com/doi/pdf/10.1080/1369118X.2021.1986102 [dostęp: 10.04.2022]. ↑
- Tamże. ↑
- Tamże. ↑
- Tamże. ↑
Bartosz Frąckowiak jest kuratorem, reżyserem i badaczem kultury, a także wicedyrektorem Biennale Warszawa. W latach 2014–2017 był wicedyrektorem Teatru Polskiego w Bydgoszczy oraz kuratorem Międzynarodowego Festiwalu Prapremier. Kurator serii wykładów performatywnych organizowanych we współpracy z Fundacją Bęc Zmiana (2012). Reżyser przedstawień, m.in. Komornicka. Biografia pozorna (2012); W pustyni i w puszczy. Z Sienkiewicza i z Innych W. Szczawińskiej i B. Frąckowiaka w Teatrze Dramatycznym w Wałbrzychu (2011); wykładu performatywnego Sztuka bycia postacią (2012), Afryki Agnieszki Jakimiak (2014), Granic Julii Holewińskiej (2016), Workplace Natalii Fiedorczuk (2017) oraz dokumentalno-śledczego spektaklu Modern Slavery (2018). Publikował w pismach teatralnych i społeczno-kulturalnych: „Autoportret”, „Dialog”, „Didaskalia”, „Krytyka Polityczna”, „Teatr”. Wykładowca SWPS w Warszawie, współkurator I i II edycji Biennale Warszawa.