

1. Nieco oświecenia w kwestii mechanizacji rozumu
Nooskop to kartografia granic sztucznej inteligencji pomyślana jako prowokacja zarówno wobec informatyki, jak i humanistyki. Każda mapa pokazuje tylko część perspektywy, jest sposobem wywołania debaty. Również i ta mapa jest manifestem – manifestem dysydentów SI. Jej głównym celem jest rzucenie wyzwania mistyfikacjom sztucznej inteligencji. Po pierwsze jako technicznej definicji inteligencji, a po drugie jako formie politycznej, która miałaby być autonomiczna względem społeczeństwa i tego, co ludzkie[1]. W wyrażeniu „sztuczna inteligencja” przymiotnik „sztuczna” jest nośnikiem mitu o autonomii technologii – wskazuje na karykaturalne „pozaludzkie umysły”, które samodzielnie reprodukują się in silico, lecz w rzeczywistości przysłania dwa procesy prawdziwej alienacji: rosnącą geopolityczną autonomię firm technologicznych i zanikanie autonomii pracowników na całym świecie. Nowoczesny projekt mechanizacji ludzkiego umysłu w XXI wieku najwyraźniej zmutował w korporacyjny reżim ekstraktywizmu wiedzy i poznawczego kolonializmu[2]. Nie ma w tym nic dziwnego, skoro algorytmy uczenia maszynowego są najmocniejszymi algorytmami do kompresowania informacji.
Celem mapy nooskopu jest sekularyzacja SI – zmiana jej statusu ideologicznego z „inteligentnej maszyny” na narzędzie wiedzy. Zamiast odwoływać się do legend o pozaludzkim poznaniu rozsądniej byłoby uznać uczenie maszynowe za przyrząd do powiększania wiedzy, pomagający dostrzegać cechy, wzorce i korelacje w przepastnych przestrzeniach danych poza zasięgiem człowieka. W historii nauki i technologii już się to zdarzało: przyrządy optyczne pełniły taką rolę w dziejach astronomii i medycyny[3]. Jeśli wpisać je w tradycję nauki, uczenie maszynowe jest jedynie nooskopem, przyrządem służącym do spoglądania na przestrzeń wiedzy i nawigowania po niej (od greckiego skopein „badać, patrzeć” i noos „wiedza”).
Diagram nooskopu opiera się na pomyśle Gottfrieda Wilhelma Leibniza i sięga do przyrządów optycznych jako analogii dla struktury całego oprzyrządowania uczenia maszynowego. By przedstawić moc swojego calculus ratiocinator i „znaków graficznych lub umownych” (był to pomysł, by zaprojektować numeryczny, uniwersalny język, w którym można by zakodować i rozwiązać wszystkie problemy ludzkiego rozumowania), Leibniz posłużył się analogią do przyrządów powiększania obrazu, takich jak mikroskop i teleskop. Pisał: „Śmiem twierdzić, że to[4] właśnie stanowi ostateczny wysiłek ducha ludzkiego, a kiedy projekt zostanie wykonany, osiągnięcie szczęścia będzie zależało już tylko od ludzi, posiądą bowiem narzędzie, które nie mniej posłuży do wywyższenia rozumu, niż teleskop służy do wzmocnienia wzroku”[5]. Nie chodzi nam o to, by po raz kolejny mówić o opozycji między kulturami jakościowymi i ilościowymi, ale lepiej nie podążać za credo Leibniza. Kontrowersji nie da się przeliczyć w sposób jednoznaczny. Uczenie maszynowe nie jest najwyższą formą inteligencji.
W przyrządy pomiaru i postrzegania zawsze wbudowane są pewne odchylenia. Tak jak soczewki mikroskopu czy teleskopu nigdy nie mają idealnej gładkości i krzywizny, tak samo logiczne soczewki uczenia maszynowego zawierają usterki i błędy[6]. Zrozumieć uczenie maszynowe i udokumentować jego wpływ na społeczeństwo to zbadać, w jakim stopniu społeczne dane ulegają dyfrakcji i zniekształceniu przez owe soczewki. Jest to temat ogólnie znany jako dyskusja nad błędem systematycznym w SI, ale polityczne implikacje logicznej formy uczenia maszynowego są głębsze. Uczenie maszynowe nie sprowadza nowych wieków ciemnych, lecz wiek zniekształconej racjonalności, w której episteme przyczynowości zostaje zastąpione przez episteme korelacji. Jeszcze ogólniej rzecz biorąc, SI to nowy reżim prawdy, dowodzenia naukowego, społecznej normy i racjonalności, który często przybiera kształt halucynacji statystycznej. Ten diagram-manifest to nasz sposób, by powiedzieć, że SI, król obliczeń (patriarchalna fantazja zmechanizowanej wiedzy, „naczelnego algorytmu” i automatu alfa), jest nagi. Tutaj ukradkiem zaglądamy do jego czarnej skrzynki.

O wynalezieniu metafor jako narzędzia powiększania wiedzy. Emanuele Tesauro, Il canocchiale aristotelico [Teleskop Arystotelesa], fronton edycji z 1670 roku, Turyn.
2. Linia montażowa uczenia maszynowego: dane, algorytm, model
Historia SI to historia eksperymentów, maszyn, które zawodzą, akademickich sporów i okresów epickiej rywalizacji o finansowanie przez armię, znanych powszechnie jako „zimy SI”[7]. Chociaż dziś korporacyjna SI opisuje swą moc językiem czarnej magii i „nadludzkiego poznania”, obecne rozwiązania nadal są w fazie eksperymentalnej[8]. SI jest teraz na tym samym etapie, co maszyna parowa przed odkryciem praw termodynamiki, koniecznych do wyjaśnienia i kontroli jej pracy. Podobnie dziś istnieją wydajne sieci neuronowe rozpoznające obraz, ale nie ma teorii uczenia się, która wyjaśniałaby, dlaczego tak dobrze działają i dlaczego tak bardzo zawodzą. Jak w przypadku każdego odkrycia, paradygmat uczenia maszynowego budował się powoli, w tym wypadku przez ostatnie pół wieku. Naczelny algorytm nie pojawił się z dnia na dzień. Trwa raczej stopniowe konstruowanie metod obliczeniowych, którym brak jeszcze wspólnego słownika. Dla przykładu, akademickie podręczniki uczenia maszynowego nie posługują się jednakową terminologią. Jak więc naszkicować niezbędną gramatykę uczenia maszynowego, która byłaby zwięzła i przystępna, bez wdawania się w paranoiczną zabawę w definiowanie ogólnej inteligencji?
Jako narzędzie wiedzy uczenie maszynowe składa się z przedmiotu obserwacji (zbiór treningowy), przyrządów obserwacji (algorytm uczący) i końcowej reprezentacji (model statystyczny). Zestawienie tych trzech elementów prezentujemy tu w postaci szemranego i barokowego diagramu uczenia maszynowego, ekstrawagancko nazwanego nooskopem[9]. By trzymać się analogii z przyrządami optycznymi: przepływ informacji w uczeniu maszynowym jest jak promień światła wysyłany przez dane treningowe, skompresowany przez algorytm, poddany dyfrakcji i skierowany w stronę świata przez soczewkę modelu statystycznego.
Diagram nooskopu dąży do tego, by zilustrować dwie strony uczenia maszynowego za jednym zamachem – to, jak działa, i to, jak zawodzi – przez wyliczenie jego głównych składników, jak również ukazanie szerokiego zakresu błędów, ograniczeń, przybliżeń, uprzedzeń, usterek, fałszywych rozumowań i słabości, które są wpisane w ten paradygmat[10]. Ów podwójny cel podkreśla, że SI nie jest monolitycznym wzorcem racjonalności, ale szemraną architekturą, stworzoną przez zaadaptowanie różnych technik i trików. Poza tym granice SI nie są tylko techniczne, są wybrukowane ludzkimi uprzedzeniami. Na diagramie nooskopu podstawowe komponenty uczenia maszynowego przedstawione są w centrum, ludzkie uprzedzenia i interwencje są po lewej, błędy systematyczne i ograniczenia techniczne – po prawej stronie. Soczewki symbolizują błędy i przybliżenia, reprezentują kompresję i zniekształcenie przepływu informacji. Całkowity błąd uczenia maszynowego jest reprezentowany przez środkową soczewkę modelu statystycznego, w której dyfrakcji ulega postrzeganie świata.
Ograniczenia SI są dziś dostrzegane dzięki dyskusji o błędzie systematycznym – wzmocnieniu przez algorytmy dyskryminacji ze względu na płeć, rasę, sprawność fizyczną i klasę społeczną. W przypadku uczenia maszynowego konieczne jest rozróżnienie błędu historycznego, błędu zbioru danych i błędu algorytmu, z których każdy występuje na innym etapie przepływu informacji[11]. Historyczna stronniczość (albo stronniczość świata) daje się dostrzec w społeczeństwie już przed interwencją technologii. Niemniej naturalizacja tej stronniczości, to znaczy wcielenie po cichu nierówności w neutralną z pozoru technologię, jest sama w sobie szkodliwa[12]. Parafrazując Michelle Alexander, Ruha Benjamin nazywa to Nowym Jimem Kodem[13]: „przyjęcie nowych technologii, które odbijają i reprodukują istniejące nierówności, a które są przedstawiane i postrzegane jako bardziej obiektywne czy bardziej postępowe niż dyskryminacyjne systemy z poprzedniej epoki”[14]. Błąd systematyczny danych pojawia się w zbiorze podczas przygotowywania danych treningowych przez pracowników. Najdelikatniejsza część tego procesu to oznaczanie danych, w czasie którego stare, konserwatywne taksonomie mogą dawać zniekształcony obraz świata, przekłamywać zróżnicowanie społeczne i wyostrzać społeczne hierarchie (zobacz niżej przykład ImageNetu).
Stronniczość algorytmu (znana też jako błąd maszynowy, błąd systematyczny albo obciążenie modelu, szczególnie istotne w diagramie nooskopu) wzmacnia jeszcze stronniczość historyczną i stronniczość zbioru danych za sprawą algorytmów uczenia maszynowego. Problem stronniczości wyrasta przede wszystkim z tego, że algorytmy uczenia maszynowego są jednymi z najbardziej skutecznych narzędzi kompresji danych, co rodzi problemy z dokładnością, dyfrakcją i utratą informacji[15]. Od najdawniejszych czasów algorytm był procedurą natury ekonomicznej, zaprojektowaną po to, by osiągnąć rezultat w jak najmniejszej liczbie kroków i przy zużyciu jak najmniejszej ilości zasobów: czasu, energii i pracy[16]. W wyścigu zbrojeń między firmami SI wciąż chodzi o znalezienie najprostszych i najszybszych algorytmów, dzięki którym można spieniężać dane. Chociaż kompresja informacji wytwarza maksymalną stopę zwrotu dla korporacyjnej SI, to ze społecznego punktu widzenia jest źródłem dyskryminacji i utraty różnorodności kulturowej.
Tak jak społeczne konsekwencje SI są powszechnie ujmowane jako zjawisko stronniczości, tak jej techniczne ograniczenia są znane jako problem czarnej skrzynki. Efekt czarnej skrzynki to zjawisko faktycznie występujące w głębokich sieciach neuronowych (które filtrują informację tak bardzo, że nie da się odtworzyć ich łańcucha rozumowania), ale stało się ono utartą wymówką na rzecz opinii, że systemy SI są nie tylko tajemnicze i nieprzeniknione, ale wręcz „pozaludzkie” i że nie poddają się kontroli[17]. Efekt czarnej skrzynki to część natury każdego eksperymentalnego urządzenia na wczesnym etapie jego rozwoju (już wspomnieliśmy, działanie maszyny parowej pozostawało przez pewien czas zagadką, nawet po tym, jak pomyślnie przeszła testy). Prawdziwym problemem jest retoryka czarnej skrzynki, bliska uczuciom zakorzenionym w teoriach spiskowych, w których SI to tajemna moc, której nie da się poznać, zgłębić ani politycznie kontrolować.
3. Zbiór treningowy: społeczne źródła inteligencji maszynowej
Masowa cyfryzacja, która rozszerzała swój zasięg wraz z internetem w latach dziewięćdziesiątych i rozrosła się wraz z centrami danych w pierwszej dekadzie XXI wieku, udostępniła ogromne zasoby danych, które po raz pierwszy w historii stały się darmowe i były nieuregulowane prawnie. Reżim ekstraktywizmu wiedzy (znany wówczas jako Big Data) stopniowo zaczął wykorzystywać bardzo wydajne algorytmy do wydobywania informacji z ogólnodostępnych źródeł danych, głównie po to, by przewidywać zachowania konsumentów i sprzedawać reklamy. Ekonomia wiedzy przekształciła się w nową formę kapitalizmu, nazywanego przez różnych autorów kapitalizmem kognitywnym, a później kapitalizmem nadzoru[18]. Zalew informacji w internecie, ogromne centra danych, szybsze mikroprocesory i algorytmy służące do kompresji danych – wszystko to położyło fundamenty pod powstanie monopoli SI w XXI wieku.
Jakiego rodzaju kulturowym i technicznym przedmiotem jest zbiór danych stanowiący źródło dla SI? Jakość danych treningowych to najważniejszy czynnik wpływający na tak zwaną inteligencję wydobywaną przez algorytmy uczenia maszynowego. Należy brać pod uwagę pewien istotny punkt widzenia, by zrozumieć SI jako nooskop. Dane to pierwsze i najważniejsze źródło wartości i informacji. Drugie to algorytmy – to właśnie one są maszynami, które wyliczają model na podstawie wartości i informacji. Dane treningowe nie są jednak nigdy surowe, niezależne ani bezstronne (już same w sobie są „algorytmiczne”)[19]. Przycinanie, formatowanie i edycja zbiorów treningowych to przedsięwzięcie pracochłonne i delikatne, prawdopodobnie istotniejsze dla końcowego rezultatu niż parametry techniczne, które kontrolują algorytm uczący. Akt wyboru tego, a nie innego źródła danych to głęboki znak ludzkiej interwencji w dziedzinę sztucznych umysłów.

Zbiór treningowy to twór kulturowy, a nie tylko techniczny. Składa się zwykle z danych wejściowych, które są połączone z idealnymi danymi wyjściowymi, na przykład obrazki z ich opisami, które nazywane są także etykietami lub metadanymi[20]. Kanonicznym przykładem może być kolekcja muzealna wraz z jej archiwum, w którym dzieła sztuki są uporządkowane według metadanych, takich jak autor, rok, technika itp. Proces semiotyczny przypisania nazwy lub kategorii do obrazu nigdy nie jest bezstronny; ten proces zostawia kolejny wyraźny ślad wpływu człowieka na ostateczny wynik poznania maszynowego. Zbiór danych treningowych dla uczenia maszynowego powstaje zazwyczaj w następujących krokach:
- Produkcja – praca lub zjawiska, które wytwarzają informację;
- Uchwycenie – zakodowanie informacji do formatu danych przy pomocy jakiegoś narzędzia;
- Formatowanie – uporządkowanie danych w zbiór danych;
- Etykietowanie – w uczeniu nadzorowanym zaklasyfikowanie danych do kategorii (metadanych).
Inteligencja maszynowa jest trenowana na ogromnych zbiorach danych, gromadzonych w sposób, który nie jest ani technicznie, ani społecznie bezstronny. Surowe dane nie istnieją, ponieważ są zależne od ludzkiej pracy, danych osobistych i zachowań społecznych, które kumulują się w długich okresach, w rozległych sieciach i z użyciem kontrowersyjnych taksonomii[21]. Najważniejsze zbiory danych treningowych dla uczenia maszynowego (MNIST, ImageNet, Labelled Faces in the Wild) mają swój początek w korporacjach, na uczelniach i w agencjach wojskowych globalnej Północy. Przy bliższym spojrzeniu można wyraźnie dostrzec podział pracy, który wdziera się do globalnego Południa za pomocą platform crowdsourcingowych, wykorzystywanych do edycji i walidacji danych[22]. Przypowieść o zbiorach ImageNetu pokazuje problemy wielu zbiorów danych SI. ImageNet to zbiór treningowy dla uczenia głębokiego, który stał się de facto głównym punktem odniesienia dla algorytmów rozpoznawania obrazów: rewolucja uczenia głębokiego zaczęła się, kiedy Alex Krizhevsky, Ilya Sutskever i Geoffrey Hinton wygrali doroczny konkurs ImageNetu swoją neuronową siecią konwolucyjną AlexNet[23]. ImageNet został uruchomiony przez informatyka Fei-Fei Li w 2006 roku[24]. Fei-Fei Li miał trzy intuicje dotyczące tego, jak zbudować wiarygodny zbiór danych do rozpoznawania obrazów. Po pierwsze, ściągnąć miliony darmowych obrazów z serwisów sieciowych takich jak Flickr i Google. Po drugie, zaadaptować komputacyjną taksonomię WordNet do etykiet obrazów[25]. Po trzecie, przekazać pracę polegającą na nadawaniu etykiet milionom obrazów przy pomocy platformy crowdsourcingowej Amazon Mechanical Turk. Na szarym końcu (oraz na końcu taśmy produkcyjnej) anonimowi robotnicy z całego świata dostawali kilka centów zapłaty za wykonanie zadania – przypisanie obrazom setek etykiet na minutę zgodnie z taksonomią WordNetu. W wyniku ich pracy powstał kontrowersyjny konstrukt kulturowy. Zajmująca się SI uczona Kate Crawford i artysta Trevor Paglen ujawnili osad rasistowskich i seksistowskich kategorii w taksonomii ImageNetu (chociażby zakres kategorii „porażka, nieudacznik, przegryw, osoba przegrana” dla stu dowolnych zdjęć ludzi)[26].
Żarłoczny ekstraktywizm danych dla SI wywołał niespodziewaną reakcję w kulturze cyfrowej: na początku XXI wieku Lawrence Lessig nie mógł przewidzieć, że wielkie repozytorium obrazów dostępnych online na licencji Creative Commons dziesięć lat później stanie się nieuregulowanym prawnie zasobem dla technologii rozpoznawania twarzy służących nadzorowi. W podobny sposób dane osobiste są stale wcielane w prywatne zbiory danych dla uczenia maszynowego. W 2019 artysta i badacz SI Adam Harvey po raz pierwszy ujawnił odbywające się bez pytania o zgodę użycie prywatnych zdjęć w zbiorach treningowych do rozpoznawania twarzy. Rewelacje Harveya skłoniły Uniwersytet Stanforda, Uniwersytet Duke i Microsoft do wycofania swoich zbiorów danych w atmosferze wielkiego skandalu[27]. Dostępne online zbiory danych zmuszają do zadawania pytań o suwerenność danych i o prawa obywatelskie, a reakcja tradycyjnych instytucji jest w tej sprawie bardzo powolna (zobacz europejskie Ogólne rozporządzenie o ochronie danych)[28]. O ile 2012 to rok, w którym zaczęła się rewolucja uczenia głębokiego, o tyle 2019 jest rokiem, w którym odkryto, że jego źródła są zatrute.

Wzorce kombinatoryczne i pismo kufickie, zwój z Topkapi, ok. 1500, Iran.
4. Historia SI jako automatyzacji postrzegania
Potrzeba odczarowania SI (przynajmniej z technicznego punktu widzenia) została zauważona również w świecie korporacji. Szef Facebook AI i ojciec chrzestny konwolucyjnych sieci neuronowych Yann LeCun powtarza, że współczesne systemy SI to wyrafinowane wersje nie zdolności poznawczych, ale percepcji. Podobnie diagram Nooskopu eksponuje szkielet czarnej skrzynki SI i pokazuje, że SI nie jest myślącą maszyną, tylko algorytmem, który rozpoznaje wzorce. Skoro wspomnieliśmy o rozpoznawaniu wzorców, to musimy rozwinąć kilka kwestii. Czym w ogóle jest wzorzec? Czy wzorzec jest bytem wyłącznie wizualnym? Co to znaczy odczytywać zachowania społeczne jako wzorce? Czy rozpoznawanie wzorców to wyczerpująca definicja inteligencji? Najprawdopodobniej nie. Aby wyjaśnić te kwestie, dobrze będzie przedsięwziąć krótką wyprawę do archeologii SI.
Archetypem maszyny do rozpoznawania obrazu jest perceptron Franka Rosenblatta. Został on wynaleziony w 1957 roku w Laboratorium Aeronautycznym Cornell w Buffalo w stanie Nowy Jork, a jego nazwa to skrót od „automat percepcyjny i rozpoznający” (Perceiving and Recognizing Automaton)[29]. Dysponując matrycą składającą się z 20×20 fotoreceptorów, perceptron może nauczyć się rozpoznawać proste litery. Wzorzec wizualny zostaje zapisany jako ślad na sieci sztucznych neuronów, które wraz z pojawianiem się podobnych obrazów przesyłają impuls i w efekcie aktywują pojedynczy neuron na wyjściu. Neuron na wyjściu przesyła 1=prawda, jeśli dany obraz został rozpoznany, lub 0=fałsz, jeśli obraz nie został rozpoznany.
Automatyzacja postrzegania, rozumiana jako wizualny montaż pikseli na obliczeniowej taśmie produkcyjnej, była pierwotnie wpisana implicite w wizję sztucznych sieci neuronowych McCullocha i Pittsa[30]. Kiedy algorytm rozpoznawania schematów wizualnych przetrwał „zimę SI” i udowodnił swoją wydajność pod koniec pierwszej dekady XXI wieku, znalazł zastosowanie również w niewizualnych zbiorach danych, co właściwie zapoczątkowało wiek uczenia głębokiego (użycie techniki rozpoznawania wzorców do wszystkich rodzajów danych, nie tylko wizualnych). Dziś w przypadku samochodów autonomicznych wzorce, jakie musi rozpoznać maszyna, to obiekty w scenariuszu drogowym. W przypadku automatycznego tłumaczenia rozpoznawane wzorce to najczęstsze sekwencje wyrazów w tekstach dwujęzycznych. Z perspektywy numerycznej wszystkie rzeczy takie jak obraz, ruch, kształt, styl i decyzja etyczna, niezależnie od ich złożoności, można opisać jako rozkład statystyczny wzorca. W tym sensie rozpoznawanie wzorców stało się nową techniką kulturową stosowaną w różnych dziedzinach. Na potrzeby wyjaśnienia nooskop został opisany jako maszyna operująca w trzech modalnościach: trenowanie, klasyfikacja i predykcja. Bardziej intuicyjnie można nazwać te modalności: wydobywanie wzorców, rozpoznawanie wzorców, generowanie wzorców.
Perceptron Rosenblatta był pierwszym algorytmem, który wytyczył drogę uczeniu maszynowemu, jakie znamy dzisiaj. Zanim ugruntowało się określenie „informatyka”, dziedzina ta była nazywana „geometrią obliczeniową”, a przez samego Rosenblatta – „konekcjonizmem”. Zadaniem tamtych sieci neuronowych było obliczanie inferencji statystycznej. Sieć neuronowa nie oblicza samego wzorca, tylko jego rozkład statystyczny. Prześlizgując się zaledwie po powierzchni antropomorficznego marketingu SI, można znaleźć jeszcze jeden techniczny i kulturowy obiekt, który warto przebadać: model statystyczny. Czym jest model statystyczny w uczeniu maszynowym? Jak się go oblicza? Jaka jest relacja między modelem statystycznym a ludzkim poznaniem? To kluczowe kwestie, które należy wyjaśnić. W ramach pracy demistyfikacyjnej, którą należy wykonać (również po to, by pozbyć się pewnych naiwnych pytań), dobrze byłoby przeformułować oklepane pytanie: „Czy maszyna może myśleć?” na bardziej rozsądne z punktu widzenia teorii pytania: „Czy model statystyczny może myśleć?”, „Czy model statystyczny może rozwinąć świadomość?” itp.
5. Algorytm uczący: kompresowanie świata do modelu statystycznego
Algorytmy SI często przywoływane są jako alchemiczne formuły zdolne do destylowania „pozaludzkich” form inteligencji. Co jednak tak naprawdę robią algorytmy uczenia maszynowego? Niewiele osób, także wśród zwolenników ogólnej sztucznej inteligencji[31], zadaje sobie to pytanie. Algorytm to nazwa procesu, w którym maszyna wykonuje obliczenia. Rezultatem takich maszynowych procesów jest model statystyczny (a dokładniej coś, co nosi nazwę „algorytmicznego modelu statystycznego”). W środowisku programistów termin „algorytm” jest coraz częściej zastępowany pojęciem „model”. Owo terminologiczne pomieszanie wynika z faktu, że statystyczny model nie istnieje niezależnie od algorytmu: w jakiś sposób model statystyczny istnieje w algorytmie jako pamięć rozproszona w postaci jego parametrów. Z tego samego powodu w zasadzie nie da się zwizualizować algorytmicznego modelu statystycznego, tak jak robi się to z prostymi funkcjami matematycznymi. Mimo to warto podjąć wyzwanie.
W uczeniu maszynowym mamy do czynienia z różnymi architekturami algorytmów: prosty perceptron, głęboka sieć neuronowa, maszyna wektorów nośnych, sieć bayesowska, łańcuch Markowa, autoencoder, maszyna Boltzmanna itp. Każda z tych architektur posiada inną historię (często zakorzenioną w agencjach wojskowych i korporacjach globalnej Północy). Sztuczne sieci neuronowe były na początku prostymi strukturami obliczeniowymi, które ewoluowały do skomplikowanych struktur, kontrolowanych przez miliony parametrów wyrażanych przy pomocy kilku hiperparametrów[32]. Dla przykładu, konwolucyjne sieci neuronowe są opisywane przez ograniczony zestaw hiperparametrów (liczby warstw, ilości neuronów na każdej warstwie, rodzaju połączenia, zachowania neuronów itp.), które rzutują kompleksową topologię tysięcy sztucznych neuronów wraz z milionami parametrów. Algorytm zaczyna jako czysta karta i – w trakcie procesu nazywanego trenowaniem albo „uczeniem się z danych” – dostosowuje swoje parametry, póki nie uzyska dobrej reprezentacji danych wejściowych. W rozpoznawaniu obrazów, jak wykazano, proces obliczeniowy milionów parametrów dąży do rozwiązania w prostej binarnej danej wyjściowej: 1=prawda, przedstawiony obraz został rozpoznany, albo 0=fałsz, przedstawiony obraz nie został rozpoznany[33].

Żeby w przystępny sposób wyjaśnić związek pomiędzy algorytmem a modelem, spójrzmy na kompleksowy algorytm Inception v3, oparty na głębokiej konwolucyjnej sieci neuronowej służącej do rozpoznawania obrazów, zaprojektowany przez Google i trenowany na zbiorze danych pochodzących z ImageNetu. Mówi się, że Inception v3 posiada dokładność na poziomie 78% w identyfikowaniu poprawnych opisów dla obrazów, jednak w tym wypadku wydajność „maszynowej inteligencji” może być również mierzona stosunkiem rozmiaru danych treningowych do rozmiaru algorytmu trenującego (lub modelu). ImageNet zawiera 14 milionów obrazów z przypisanymi opisami, które zajmują mniej więcej 150 GB pamięci. Tymczasem, Inception v3, którego zadaniem jest reprezentacja informacji zawartych w ImageNet, waży jedynie 92 MB. Stosunek kompresji pomiędzy zbiorem treningowym i modelem częściowo opisuje również poziom dyfrakcji informacji. Tabela z dokumentacji biblioteki Keras zestawia ze sobą te wartości (liczbę parametrów, głębokość warstwy, wymiar pliku i dokładność) dla głównych modeli rozpoznawania obrazów[34]. Jest to brutalny, ale efektywny sposób na pokazanie relacji między modelem a danymi po to, by zademonstrować, w jaki sposób „inteligencja” algorytmów jest mierzona i szacowana w społeczności programistów.
Dokumentacja poszczególnych modeli
| Model | Rozmiar | Dokładność top-1 | Dokładność top-5 | Parametery | Liczba warstw |
|---|---|---|---|---|---|
| Xception | 88 MB | 0.790 | 0.945 | 22,910,480 | 126 |
| VGG16 | 528 MB | 0.713 | 0.901 | 138,357,544 | 23 |
| VGG19 | 549 MB | 0.713 | 0.900 | 143,667,240 | 26 |
| ResNet50 | 98 MB | 0.749 | 0.921 | 25,636,712 | – |
| ResNet101 | 171 MB | 0.764 | 0.928 | 44,707,176 | – |
| ResNet152 | 232 MB | 0.766 | 0.931 | 60,419,944 | – |
| ResNet50V2 | 98 MB | 0.760 | 0.930 | 25,613,800 | – |
| ResNet101V2 | 171 MB | 0.772 | 0.938 | 44,675,560 | – |
| ResNet152V2 | 232 MB | 0.780 | 0.942 | 60,380,648 | – |
| InceptionV3 | 92 MB | 0.779 | 0.937 | 23,851,784 | 159 |
| InceptionResNetV2 | 215 MB | 0.803 | 0.953 | 55,873,736 | 572 |
| MobileNet | 16 MB | 0.704 | 0.895 | 4,253,864 | 88 |
| MobileNetV2 | 14 MB | 0.713 | 0.901 | 3,538,984 | 88 |
| DenseNet121 | 33 MB | 0.750 | 0.923 | 8,062,504 | 121 |
| DenseNet169 | 57 MB | 0.762 | 0.932 | 14,307,880 | 169 |
| DenseNet201 | 80 MB | 0.773 | 0.936 | 20,242,984 | 201 |
| NASNetMobile | 23 MB | 0.744 | 0.919 | 5,326,716 | – |
| NASNetLarge | 343 MB | 0.825 | 0.960 | 88,949,818 | – |
Modele statystyczne od zawsze wpływały na kulturę i politykę. Nie pojawiły się dopiero wraz z uczeniem maszynowym – uczenie maszynowe jest jedynie nowym sposobem automatyzacji technik modelowania statystycznego. Kiedy Greta Thunberg ostrzega: „Słuchajcie nauki”, to jako uczennica dobra z matematyki ma na myśli: „Słuchajcie statystycznych modeli nauk o klimacie”. Bez statystycznych modeli nie ma nauk o klimacie; bez nauk o klimacie nie ma aktywizmu klimatycznego. Nauki o klimacie są dobrym przykładem, od którego warto zacząć, żeby zrozumieć modele statystyczne. Globalne ocieplenie wyliczono przez zebranie najpierw ogromnej ilości danych na temat temperatur na Ziemi z każdego dnia roku, a następnie zastosowano matematyczny model, który wyznacza krzywą zmienności temperatury z przeszłości, aby powstały w ten sposób wzorzec rzutować na przyszłość[35]. Modele klimatyczne są artefaktami o naturze historycznej, testowanymi i omawianymi w społeczności naukowej, a dzisiaj również poza nią[36]. Modele maszynowe zaś pozostają niejawne i niedostępne dla szerszej publiczności. Biorąc pod uwagę to, jak wokół konstruktów matematycznych sztucznej inteligencji tworzą się mity i uprzedzenia społeczne, rzeczywiście zapoczątkowała ona erę statystycznej fantastyki naukowej. Nooskop jest projektorem w tym ogromnym statystycznym kinie.
6. Wszystkie modele są błędne, ale niektóre są użyteczne
„Wszystkie modele są błędne, ale niektóre są użyteczne” – kanoniczne już twierdzenie brytyjskiego statystyka George’a Boxa od dawna ujmuje logiczne ograniczenia statystyki i uczenia maszynowego[37]. Jednakże ta maksyma często jest wykorzystywana w celu uprawomocnienia stronniczości zarówno korporacyjnej, jak i państwowej sztucznej inteligencji. Informatycy przekonują, że ludzkie poznanie odzwierciedla zdolność do wyodrębniania i aproksymacji wzorców. Czemu maszyny nie miałyby robić tego samego, skoro też aproksymują? W argumencie tym retorycznie powtórzone jest to, że „mapa nie jest terytorium”. Brzmi to sensownie. Należy jednak podkreślić, że sztuczna inteligencja jest mocno skompresowaną i zniekształconą mapą terytorium i że ta mapa, podobnie jak wiele form automatyzacji, nie poddaje się negocjacjom w sferze publicznej. Sztuczna inteligencja jest mapą terytorium bez społecznego dostępu i bez społecznej zgody[38].
W jaki sposób uczenie maszynowe kreśli statystyczną mapę świata? Zwróćmy się w stronę specyficznej kwestii, jaką jest rozpoznawanie obrazów (podstawowa forma pracy percepcji, która została skodyfikowana i zautomatyzowana jako rozpoznawanie wzorców)[39]. Aby sklasyfikować obraz, algorytm wykrywa krawędzie obiektu, które są statystycznym rozkładem ciemnych pikseli otoczonych pikselami jasnymi (typowy wzorzec wizualny). Algorytm nie wie, co jest treścią obrazu, nie postrzega go w taki sam sposób jak człowiek, jedynie liczy piksele, numeryczne wartości jasności i bliskości. Jest tak zaprogramowany, aby rejestrować jedynie ciemne krawędzie profilu (żeby dopasować się do pożądanego wzorca), a nie wszystkie piksele na obrazie (co skutkowałoby nadmiernym dopasowaniem i powtórzeniem całego pola widzenia). Model statystyczny jest prawidłowo wytrenowany, jeżeli w sposób elegancki dopasuje tylko istotne wzorce danych treningowych i zastosuje te wzorce do nowych danych „na wolności”. Jeżeli model nauczy się zbioru danych treningowych zbyt dobrze, rozpozna jedynie dokładne przypasowania do oryginalnych wzorców i „na wolności” przeoczy te bardzo do nich podobne. W takim wypadku model jest nadmiernie dopasowany, ponieważ nauczył się wszystkiego (łącznie z szumem) i nie jest w stanie odróżnić wzorca od tła. Model jest z kolei niedopasowany, kiedy nie jest w stanie wykrywać znaczących wzorców z danych treningowych. Pojęcia nadmiernego dopasowania, dopasowania i niedopasowania danych można zwizualizować na płaszczyźnie kartezjańskiej.

Wyzwanie związane z nadzorowaniem uczenia maszynowego polega na kalibrowaniu równowagi pomiędzy niedopasowaniem i nadmiernym dopasowaniem danych, co jest trudnym zadaniem ze względu na różne maszynowe błędy systematyczne. Uczenie maszynowe jest pojęciem, które podobnie jak sztuczna inteligencja antropomorfizuje technologię: uczenie maszynowe nie poznaje prawdziwego znaczenia słowa, jak robi to człowiek; uczenie maszynowe po prostu mapuje statystyczną dystrybucję numerycznych wartości i rysuje matematyczną funkcję, która przy odrobinie szczęścia stanowi przybliżenie ludzkiego rozumowania. Z tego właśnie powodu uczenie maszynowe może rzucić nowe światło na sposób, w jaki ludzie rozumują.
Model statystyczny algorytmu uczenia maszynowego jest również przybliżeniem w tym sensie, że stara się odgadnąć brakujące fragmenty grafu danych: albo przez interpolację, która jest prognozowaniem wyjścia y w znanym interwale wejścia x w zbiorze danych treningowych, albo przez ekstrapolację, która jest prognozowaniem wyjścia y poza granicami x, często z większym ryzykiem niedokładności. Tym jest dzisiaj „inteligencja” w inteligencji maszynowej: ekstrapolowaniem funkcji nieliniowej poza granice znanych danych. Jak trafnie ujmuje to Dan McQuillian: „Nie ma inteligencji w sztucznej inteligencji, ani żadnego uczenia się, choć jej techniczną nazwą jest uczenie maszynowe; to jest po prostu matematyczna optymalizacja”[40].
Należy jednak przypomnieć, że „inteligencja” uczenia maszynowego nie opiera się na dokładnych formułach analizy matematycznej, ale na algorytmach aproksymacji metodą siłową. Kształt funkcji korelacji pomiędzy wejściem x i wyjściem y jest liczony algorytmicznie, krok po kroku, przez uciążliwe mechaniczne procesy stopniowej regulacji (na przykład metodą gradientu prostego), które są odpowiednikiem rachunku różniczkowego Leibniza i Newtona. Sieci neuronowe są uważane za jedne z najbardziej wydajnych algorytmów, ponieważ przy wystarczającej liczbie warstw neuronów i obfitych zasobach obliczeniowych metody różniczkowe mogą przybliżyć kształt dowolnej funkcji[41]. Stopniowe przybliżanie funkcji metodą siłową jest podstawową cechą współczesnej sztucznej inteligencji, i tylko z tej perspektywy można zrozumieć jej potencjał i ograniczenia – szczególnie jej rosnący ślad węglowy (trenowanie głębokich sieci neuronowych wymaga ogromnych zasobów energii, ponieważ metoda gradientu prostego i inne algorytmy trenujące działają na podstawie ciągłego nanoszenia nieskończenie małych korekt)[42].
7. Świat na wektor
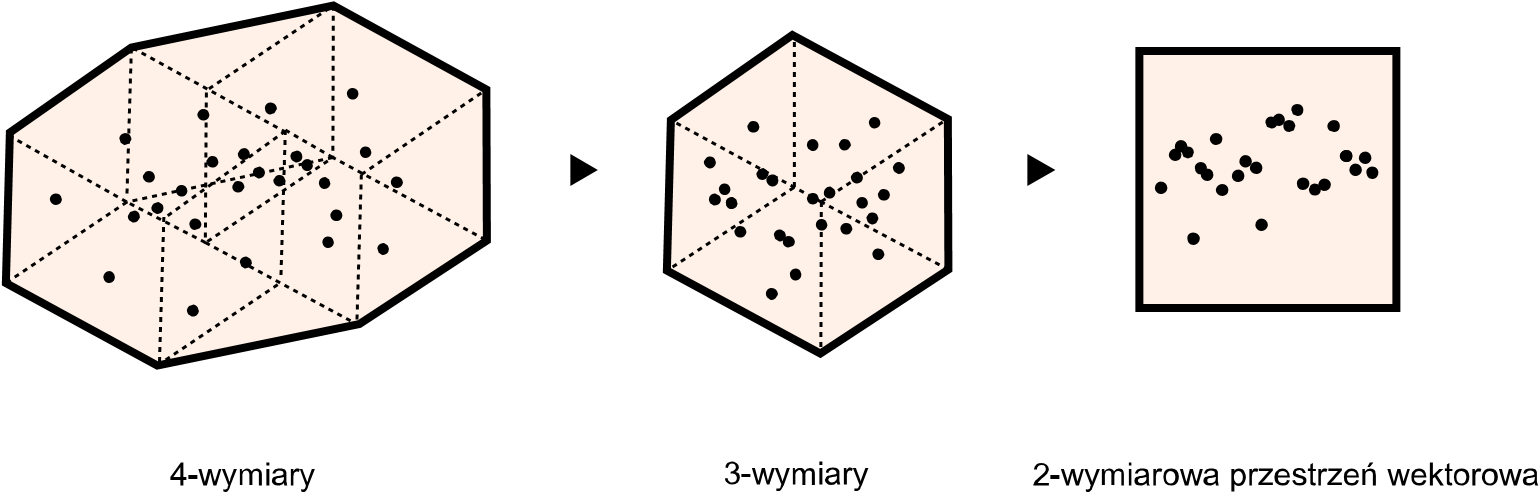
Pojęcia dopasowania danych, nadmiernego dopasowania, niedopasowania, interpolacji i ekstrapolacji można łatwo zwizualizować w dwóch wymiarach, jednak modele statystyczne zwykle działają na wielowymiarowych przestrzeniach danych. Dane, zanim zostaną przeanalizowane, zostają zakodowane do wielowymiarowej przestrzeni wektorów, która jest mało intuicyjna. Czym jest przestrzeń wektorów i dlaczego jest ona wielowymiarowa? Cardon, Cointet i Mazière opisują wektoryzację danych w ten oto sposób:
Sieć neuronowa wymaga, żeby dane wejściowe przybrały formę wektora. W związku z tym świat musi być najpierw zakodowany w postaci czysto cyfrowej wektorowej reprezentacji. Niektóre obiekty, takie jak obrazy, dają się naturalnie przełożyć na wektory, jednak pozostałe muszą zostać „osadzone” w przestrzeni wektorowej, zanim będzie możliwe ich policzenie lub zaklasyfikowanie w sieciach neuronowych. Tak dzieje się w przypadku tekstu, który jest przykładem prototypowym. Aby wprowadzić słowo do sieci neuronowej, technika Word2vec „osadza” je w przestrzeni wektorowej, która mierzy jego odległość od innych słów w korpusie. W ten sposób słowa otrzymują pozycję w przestrzeni o kilkuset wymiarach. Zaletą takiej reprezentacji jest wielość operacji, które ta transformacja umożliwia. Dwa pojęcia, które według wyliczeń znajdują się blisko siebie w tej przestrzeni, są równie bliskie semantycznie; mówi się wówczas, że te reprezentacje są rozłożone następująco: wektor pojęcia „apartament” [˗0.2, 0.3, ˗4.2, 5.1…] będzie podobny do wektora pojęcia „dom” [˗0.2, 0.3, ˗4.0, 5.1…]. […] Przetwarzanie języka naturalnego było prekursorem w „osadzaniu” słów w przestrzeni wektorowej, a obecnie jesteśmy świadkami generalizacji procesu osadzania, który stopniowo rozszerza się na wszystkie obszary działania: sieci stają się punktami w przestrzeni wektorowej dzięki graph2vec, teksty pisane dzięki paragraph2vec, filmy dzięki movie2vec, znaczenia słów dzięki sens2vec, struktury molekularne dzięki mol2vec itd. Zdaniem Yanna LeCuna celem projektantów maszyn koneksjonistycznych jest przełożenie świata na wektor (world2vec)[43].
Wielowymiarowa przestrzeń wektorowa to jeden z czynników, które utrudniają uchwycenie logiki uczenia maszynowego. To nowa technika kulturowa, z którą warto się zapoznać. W szczególności cyfrowa humanistyka zajmuje się techniką wektoryzacji, dzięki której nasza kolektywna wiedza jest niewidocznie przedstawiana i przetwarzana. William Gibson w swej oryginalnej definicji cyberprzestrzeni najprawdopodobniej przewidział nadejście nie rzeczywistości wirtualnej, lecz przestrzeni wektorowej: „Graficzne odwzorowanie danych pobieranych z banków wszystkich komputerów świata. Niewyobrażalna złożoność… Świetlne linie przebiegały bezprzestrzeń umysłu, skupiska i konstelacje danych. Jak światła wielkiego miasta, coraz dalsze…”[44].

Po prawej: przestrzeń wektorowa siedmiu słów w trzech kontekstach[45]
8. Społeczeństwo klasyfikujących i przewidujących botów
Większość współczesnych zastosowań uczenia maszynowego może być opisana w nawiązaniu do dwóch modalności klasyfikacji i przewidywania, które nakreślają kontury nowego społeczeństwa kontroli i zarządzania przez statystykę. Klasyfikacja znana jest jako rozpoznawanie wzorców, natomiast przewidywanie można zdefiniować jako wytwarzanie wzorców. Nowy wzorzec jest rozpoznawany albo wytwarzany poprzez przebadanie wewnętrznego rdzenia modelu statystycznego.
Maszynową klasyfikację zazwyczaj zaprzęga się do pracy, by rozpoznała znak, obiekt albo ludzką twarz oraz przypisała odpowiednią kategorię w oparciu o taksonomię lub konwencję kulturową. Plik wejściowy (na przykład zdjęcie twarzy uchwycone przez kamerę nadzorującą) jest przetwarzany przez model w celu określenia, czy wpisuje się w jego rozkład prawdopodobieństwa, czy nie. Jeżeli tak jest, zostaje on przypisany do odpowiadającej mu etykiety na wyjściu. Od czasów perceptronu klasyfikacja była pierwotnym zastosowaniem sieci neuronowych. Z pojawieniem się uczenia głębokiego technika ta upowszechniła się w klasyfikatorach rozpoznawania twarzy wykorzystywanych zarówno przez policję, jak i producentów smartfonów.
Predykcji w uczeniu maszynowym używa się do prognozowania przyszłych trendów i zachowań na podstawie minionych, czyli do uzupełnienia informacji na podstawie jej fragmentu. W modalności predykcji próbka danych wejściowych (starter) jest używana do przewidywania brakującej części informacji – również na podstawie rozkładu statystycznego modelu (wynikiem mógłby być fragment wykresu numerycznego wybiegającego w przyszłość lub brakująca część obrazu albo pliku dźwiękowego). Nawiasem mówiąc, istnieją inne modalności uczenia maszynowego: rozkład statystyczny modelu może być dynamicznie wizualizowany dzięki technice eksploracji przestrzeni utajonej i – w ostatnich zastosowaniach – eksploracji wzorców[47].
Klasyfikacja i predykcja w uczeniu maszynowym, dziś wszechobecne, ustanawiają nowe formy inwigilacji i zarządzania. Niektóre urządzenia, takie jak autonomiczne pojazdy czy roboty przemysłowe, mogą łączyć obie modalności. Autonomiczny pojazd uczy się rozpoznawać różne obiekty na drodze (ludzi, samochody, przeszkody, znaki) i przewidywać wydarzenia na podstawie decyzji podjętych przez kierowcę-człowieka w podobnych okolicznościach. Nawet jeżeli rozpoznawanie przeszkody na drodze wydaje się gestem neutralnym (a nie jest), identyfikowanie człowieka w oparciu o kategorie płci, rasy i klasy (a w kontekście pandemii COVID-19 – jako zdrowego lub chorego), jak to robią coraz częściej instytucje państwowe, jest gestem nowego reżimu dyscyplinarnego. Pycha zautomatyzowanej klasyfikacji spowodowała odrodzenie się reakcyjnych praktyk lombrozjańskich, o których sądzono, że przeszły już do historii – takich jak automatyczne rozpoznawanie płci (Automatic Gender Recognition – AGR), „poddziedzina rozpoznawania twarzy, której celem jest algorytmiczne identyfikowanie płci osób na podstawie zdjęć lub materiałów wideo”[48].

W ostatnim czasie modalność generatywna uczenia maszynowego wywarła wpływ na kulturę: jej wykorzystanie w produkcji materiałów wizualnych zostało odebrane przez środki masowego przekazu jako przekonanie, że sztuczna inteligencja jest „kreatywna” i może w sposób autonomiczny tworzyć sztukę. Dzieło sztuki, które uważa się za wykonane przez SI, zawsze skrywa za sobą pracownika, który zastosował modalność generatywną sieci neuronowej, trenowanej na konkretnym zbiorze danych. Sieć neuronowa działa w tej modalności wstecz (idąc od mniejszej warstwy wyjścia do większej warstwy wejścia), aby wygenerować nowe wzorce po przeszkoleniu w ich klasyfikowaniu, w procesie, który zazwyczaj przebiega od większej warstwy wejścia do mniejszej warstwy wyjścia. Modalność generatywna ma jednak użyteczne zastosowania: może być użyta do weryfikacji tego, czego model się nauczył, to znaczy do pokazania, jak model „widzi świat”. Można ją wykorzystać na przykład w modelu dla samochodu autonomicznego, aby sprawdzić przewidywany scenariusz trasy do przebycia.
Popularnym pomysłem na pokazanie tego, jak model statystyczny „widzi świat”, jest Google’owski DeepDream. DeepDream to konwolucyjna sieć neuronowa bazująca na Inception (która jest trenowana na wspomnianym wyżej zbiorze danych ImageNet), zaprogramowana przez Alexandra Mordvintseva w celu wyświetlania halucynacyjnych wzorców. Mordvintsev wpadł na pomysł „odwrócenia sieci do góry nogami” przez zamianę klasyfikatora na generator przy użyciu różnych szumów lub generycznych krajobrazów jako wejścia[49]. Odkrył w ten sposób, że „sieci neuronowe, które były trenowane, żeby znajdować różnice między obrazami, mają sporo informacji potrzebnych do ich generowania”. W pierwszych eksperymentach DeepDream zewsząd zaczęły wyłaniać się skrzydła ptaka i oczy psa, ponieważ różne rasy psów i gatunki ptaków są ogromnie nadreprezentowane w ImageNet. Okazało się również, że kategoria „hantel” została wyuczona z surrealistycznie przyczepioną do tego przyrządu ludzką ręką. Dowód na to, jak wiele kategorii w ImageNet jest fałszywie przedstawionych.
Dwie podstawowe modalności klasyfikacji i generowania mogą być złożone w kolejnych architekturach, takich jak generatywne sieci przeciwstawne (Generative Adversarial Networks). W architekturze GAN sieć neuronowa będąca dyskryminatorem (tradycyjnym klasyfikatorem) powinna rozpoznawać obraz wyprodukowany przez sieć neuronową będącą generatorem, w pętli wzmocnienia, która równocześnie trenuje dwa modele statystyczne. Ze względu na niektóre zbieżne właściwości poszczególnych modeli statystycznych GAN-y bardzo dobrze sprawdziły się w generowaniu wysoce realistycznych obrazów. Z tego powodu były nadużywane do fabrykowania „deepfake’ów”[50]. Jeśli chodzi o reżim prawdy, podobne kontrowersyjne zastosowanie GAN-u ma miejsce w przypadku generowania sztucznych danych w badaniach nad rakiem, w których sieci neuronowe trenowane na źle zrównoważonym zbiorze danych zawierającym tkanki nowotworowe dopatrywały się nowotworu tam, gdzie go nie było[51]. W tym przypadku „zamiast poznawać rzeczy, zaczęliśmy je wynajdywać”, jak zauważa Fabian Offert, „przestrzeń poznania jest identyczna z przestrzenią wiedzy, którą GAN już posiadał. […] Kiedy myślimy, że widzimy przez GAN – patrząc na coś za pomocą GAN-u – właściwie patrzymy w głąb GAN-u. Wizja GAN-u nie jest rozszerzoną rzeczywistością, jest rzeczywistością wirtualną. GAN-y rozmywają poznawanie i wynajdywanie”[52]. GAN-owska symulacja nowotworu mózgu jest tragicznym przykładem opartej na sztucznej inteligencji naukowej halucynacji.
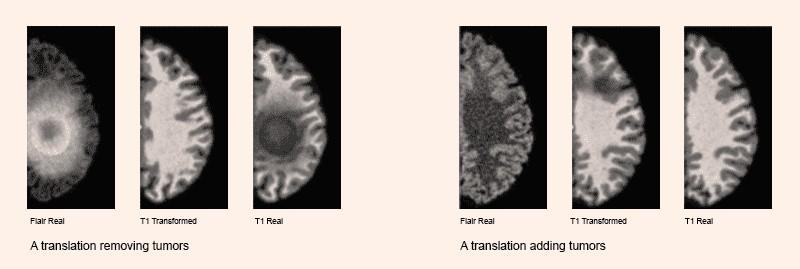
Joseph Paul Cohen, Margaux Luck and Sina Honari. „Distribution Matching Losses Can Hallucinate Features in Medical Image Translation”, 2018. Dzięki uprzejmości autorów.
9. Błędy narzędzia statystycznego: niewykrywanie tego, co nowe
Normatywna siła sztucznej inteligencji w XXI wieku powinna być szczegółowo przeanalizowana pod kątem następujących zagadnień epistemicznych: co oznacza przekształcanie zbiorowej wiedzy we wzorce oraz co oznacza kreślenie przestrzeni wektorowych i rozkładów statystycznych zachowań społecznych? Według Foucaulta już w nowożytnej Francji wykorzystywano siłę statystyki do mierzenia norm społecznych i odróżniania zachowań normalnych od anormalnych[53]. Sztuczna inteligencja z łatwością zwiększa „moc normalizacji” nowoczesnych instytucji, takich jak biurokracja, medycyna czy statystyka (w pierwotnym rozumieniu, jako posiadana przez państwo wiedza na temat jego populacji, wyrażona w formie danych liczbowych), ze względu na to, że przechodzą one w ręce korporacji zajmujących się sztuczną inteligencją właśnie. Normy instytucjonalne stały się normami komputacyjnymi: klasyfikacja podmiotu – ciał i zachowań – nie wydaje się już sprawą rejestrów publicznych, ale algorytmów i centrów danych[54]. Jak podsumowuje Paula Duarte: „racjonalność oparta na danych powinna być rozumiana jako wyraz kolonialności władzy”[55].
Zawsze jednak istnieje jakaś luka, tarcie bądź konflikt między modelami statystycznymi SI a ludzkim podmiotem, który ma być mierzony i kontrolowany. Ta logiczna luka pomiędzy modelami statystycznymi SI a społeczeństwem jest zazwyczaj omawiana jako błąd systematyczny (bias). Zostało obszernie wykazane, w jaki sposób rozpoznawanie twarzy fałszywie przedstawia mniejszości społeczne i jak na przykład czarne dzielnice są omijane przez usługi logistyczne i dostawcze oparte na sztucznej inteligencji[56]. Jeżeli dyskryminacja ze względu na płeć, rasę lub klasę społeczną jest wzmocniona algorytmami SI, jest to również częścią bardziej złożonego problemu dyskryminacji i normalizacji w logicznym rdzeniu uczenia maszynowego. Logicznym i politycznym ograniczeniem sztucznej inteligencji jest trudność, jaką technologii sprawia rozpoznawanie oraz przewidywanie nowych zdarzeń. W jaki sposób uczenie maszynowe radzi sobie z faktycznie wyjątkową anomalią, nietypowym zachowaniem społecznym czy innowacyjnym działaniem zakłócającym? Dwie modalności uczenia maszynowego pokazują ograniczenie, które nie jest wyłącznie błędem systematycznym.
Logicznym ograniczeniem maszynowej klasyfikacji i rozpoznawania wzorców jest niemożność zidentyfikowania wyjątkowej anomalii, która pojawia się po raz pierwszy, takiej jak nowa poetycka metafora, nowy żart w codziennej rozmowie czy niezwykła przeszkoda (pieszy? plastikowa torba?) na drodze. Nierozpoznanie tego, co nowe (czegoś, czego model nigdy wcześniej nie „widział”, a zatem nigdy nie przyporządkował do znanej kategorii), jest szczególnie niebezpieczne w przypadku samochodów autonomicznych i stało się już przyczyną zgonów. Przewidywanie maszynowe i generowanie wzorców wykazują podobne błędy w odgadywaniu przyszłych trendów i zachowań. Jako technika kompresji informacji uczenie maszynowe automatyzuje dyktaturę przeszłości, przeszłych taksonomii i wzorców zachowań, nad teraźniejszością. Problem ten można nazwać odrodzeniem minionego – zastosowaniem homogenicznego spojrzenia na czasoprzestrzeń, które ogranicza możliwość wystąpienia nowego wydarzenia historycznego.
Co ciekawe, w uczeniu maszynowym logiczna definicja problemu bezpieczeństwa opisuje również logiczne ograniczenie jego twórczego potencjału. Problemy charakterystyczne dla przewidywania tego, co nowe, są logicznie powiązane z tymi, które charakteryzują generację tego, co nowe, ponieważ sposób, w jaki algorytm uczenia maszynowego przewiduje trend na wykresie czasowym, jest identyczny ze sposobem, w jaki generuje nową grafikę z wyuczonych wzorców. Oklepane pytanie: „czy SI może być kreatywna?” powinno zostać przeformułowane pod względem technicznym: czy uczenie maszynowe jest w stanie tworzyć dzieła, które nie są imitacją przeszłości? Czy uczenie maszynowe jest w stanie ekstrapolować poza stylistyczne granice danych treningowych? „Kreatywność” uczenia maszynowego ogranicza się do wykrywania stylów na podstawie danych treningowych, a następnie do przypadkowej improwizacji w obrębie tych stylów. Innymi słowy, uczenie maszynowe może eksplorować i improwizować tylko w granicach logicznych wyznaczonych przez dane treningowe. Ze względu na wszystkie te kwestie, jak również na stopień kompresji informacji, bardziej trafne byłoby określenie sztuki tworzonej przez uczenie maszynowe jako sztuki statystycznej.

Lewis Fry Richardson, Weather Prediction by Numerical Process, Cambridge University Press, 1922.
Innym niewypowiedzianym błędem w uczeniu maszynowym jest to, że korelacja statystyczna między dwoma zjawiskami jest często traktowana jako zachodzący między nimi związek przyczynowy. W statystyce powszechnie przyjmuje się, że korelacja nie oznacza związku przyczynowego, co oznacza, że sam statystyczny zbieg okoliczności nie jest wystarczający do wykazania związku przyczynowego. Tragiczny przykład takiego błędu można znaleźć w pracy statystyka Fredericka Hoffmana, który w 1896 roku opublikował trzystutrzydziestostronicowy raport dla towarzystw ubezpieczeniowych, aby wykazać rasową korelację między byciem czarnym Amerykaninem a krótką oczekiwaną długością życia[57]. Przez powierzchowne eksplorowanie danych uczenie maszynowe może stworzyć dowolną korelację, która będzie postrzegana jako rzeczywista.
W 2008 roku ten błąd logiczny z dumą popełnił redaktor naczelny miesięcznika „Wired”, Chris Anderson, który ogłosił „koniec teorii”, ponieważ „potop danych sprawia, że metoda naukowa staje się przestarzała”[58]. Według Andersona, który sam nie jest ekspertem od metod naukowych i logicznego wnioskowania, korelacja statystyczna wystarcza do prowadzenia opartego o system reklamowy biznesu Google’a, wobec czego musi być wystarczająco dobra, aby automatycznie odkrywać paradygmaty naukowe. Nawet Judea Pearl, pionier sieci bayesowskich, uważa, że uczenie maszynowe ma obsesję na punkcie „dopasowywania krzywych”, czyli rejestrowania korelacji bez podawania wyjaśnień[59]. Taki błąd logiczny jest już błędem politycznym, jeśli weźmie się pod uwagę, że służby porządkowe na całym świecie przyjęły predykcyjne algorytmy policyjne[60]. Według Dana McQuillana, kiedy uczenie maszynowe jest stosowane w społeczeństwie w ten sposób, zamienia się w biopolityczny aparat prewencji, wytwarzający podmiotowości, które mogą następnie zostać uznane za przestępcze[61]. W ostatecznym rozrachunku uczenie maszynowe ze swoją obsesją na punkcie „dopasowywania krzywych” narzuca kulturę statystyczną i zastępuje tradycyjną episteme przyczynowości (i politycznej odpowiedzialności) korelacją na ślepo napędzaną przez zautomatyzowane podejmowanie decyzji.
10. Inteligencja przeciwstawna vs. sztuczna inteligencja
Do tej pory śledziliśmy statystyczne dyfrakcje i halucynacje uczenia maszynowego krok po kroku przez wiele soczewek nooskopu. W tym momencie kierunek instrumentu musi zostać odwrócony: zarówno teorie naukowe, jak i urządzenia komputacyjne, są skłonne do utrwalania perspektywy abstrakcyjnej – naukowego „punktu widzenia znikąd”, często będącego po prostu punktem widzenia władzy. Obsesyjne zgłębianie sztucznej inteligencji może strącić badacza w otchłań komputacji i iluzji, że forma techniczna oświeca społeczną. Jak zaznacza Paola Ricaurte: „ekstraktywizm danych zakłada, że wszystko jest ich źródłem”[62]. Jak wyemancypować się z wizji świata, która stawia dane w centrum? Czas uzmysłowić sobie, że to nie model statystyczny tworzy podmiot, lecz podmiot nadaje kształt modelowi statystycznemu. Granica między internalistycznymi i eksternalistycznymi badaniami SI musi się zatrzeć: podmiotowości tworzą matematykę kontroli od wewnątrz, a nie od zewnątrz. O inteligencji maszyn można powiedzieć to, co Guattari stwierdził kiedyś na temat maszyn w ogóle – ona również składa się z „hiperrozwiniętych i hiperskoncentrowanych form pewnych aspektów ludzkiej podmiotowości”[63].
Krytyczne dociekanie bada nie tylko to, jak technologia działa, lecz także to, jak się psuje; jak badani buntują się przeciwko jej normatywnej kontroli, a pracownicy sabotują jej tryby. W tym sensie zwrócenie się w kierunku praktyk hakerskich jest sposobem na zbadanie granic sztucznej inteligencji. Hakowanie to istotna metoda wytwarzania wiedzy, epistemiczna sonda wpuszczona w mrok sztucznej inteligencji[64]. Przykładowo, systemy uczenia głębokiego do rozpoznawania twarzy wyzwoliły formy aktywizmu przeciwko inwigilacji. Ludzie postanowili skorzystać z technik kamuflowania twarzy, by pozostać nierozpoznawalnymi dla sztucznej inteligencji, czyli sami stali się czarnymi skrzynkami. W dobie uczenia maszynowego tradycyjne techniki kamuflażu przeciwko inwigilacji natychmiast nabierają wymiaru matematycznego. Na przykład artysta i badacz sztucznej inteligencji Adam Harvey stworzył HyperFace – kamuflującą tkaninę, która sprawia, że algorytmy widzenia komputerowego dostrzegają wiele ludzkich twarzy tam, gdzie żadnej nie ma[65]. Dzieło Harveya nasuwa pytanie: czym jest twarz dla ludzkiego oka, a czym dla algorytmu widzenia komputerowego? Kształty na HyperFace wykorzystują tę lukę poznawczą i pokazują, jak ludzka twarz wygląda dla maszyny.
Ta luka między percepcją człowieka i maszyny pozwala na realizację coraz liczniejszych ataków przeciwstawnych.

Adam Harvey, HyperFace pattern, 2016.
Ataki przeciwstawne wykorzystują martwe punkty i słabe obszary w modelu statystycznym sieci neuronowej, zwykle po to, aby oszukać klasyfikator i sprawić, by dostrzegł coś, czego nie ma. W rozpoznawaniu obiektów przykładem ataku przeciwstawnego może być wyglądający niewinnie dla ludzkiego oka odpowiednio spreparowany obraz żółwia, błędnie sklasyfikowany przez sieć neuronową jako karabin[66]. Inne przykłady to obiekty trójwymiarowe, a nawet naklejki na znaki drogowe, które mogą wprowadzić w błąd samochody autonomiczne (jeśli na przykład spowodują odczytanie limitu prędkości 120 km/h, podczas gdy rzeczywisty limit wynosi 50 km/h)[67]. Przykłady przeciwstawne są projektowane z wykorzystaniem wiedzy o tym, czego maszyna wcześniej nie widziała. Efekt ten można osiągnąć również dzięki zastosowaniu inżynierii odwrotnej na modelu statystycznym lub poprzez zanieczyszczenie trenowanego zbioru danych. W tym ostatnim przypadku wprowadza się spreparowane dane do trenowanego zbioru przy użyciu techniki zatruwania danych. Zmienia się w ten sposób dokładność modelu statystycznego i tworzy furtkę, która może być wykorzystana do ataku przeciwstawnego[68].
Atak przeciwstawny zdaje się wskazywać na matematyczną lukę, która jest wspólna dla wszystkich modeli uczenia maszynowego: „Intrygującym aspektem przykładów przeciwstawnych jest to, że przykład wygenerowany dla jednego modelu jest często błędnie klasyfikowany przez inne modele, nawet jeśli mają one inną architekturę lub zostały przeszkolone na rozłącznych zbiorach treningowych”[69]. Ataki przeciwstawne przypominają nam o rozbieżności między percepcją ludzi i maszyn oraz o tym, że logiczne ograniczenie uczenia maszynowego ma również wymiar polityczny. Logiczną i ontologiczną granicą uczenia maszynowego jest nieposłuszny podmiot lub anomalne zdarzenie, niedające się sklasyfikować ani poddać kontroli. Podmiot algorytmicznej kontroli kontratakuje. Ataki przeciwstawne to sposób sabotażu linii produkcyjnej uczenia maszynowego poprzez odkrywanie wirtualnych przeszkód, które mogą rozregulować system kontroli. Przykład przeciwstawny jest sabotem w erze sztucznej inteligencji.
11. Praca w czasach SI
Należy wyjaśnić naturę „danych wejściowych” i „danych wyjściowych” uczenia maszynowego. Sztuczna inteligencja ma kłopoty nie tylko ze stronniczością informacji, lecz także z pracą. SI nie jest jedynie aparatem kontroli, ale również aparatem produkcji. Jak już zauważyliśmy, niewidoczna siła robocza jest zaangażowana na każdym odcinku linii montażowej (kompozycja zbioru danych, nadzór algorytmu, ocena modelu itp.). Potok niekończących się zadań przepływa z globalnej Północy na globalne Południe; platformy crowdsourcingowe z pracownikami z Wenezueli, Brazylii czy Włoch mają kluczowe znaczenie przy uczeniu „widzenia” niemieckich samochodów autonomicznych[70]. Należy podkreślić, że wbrew przekonaniu o pracy pozaludzkiej inteligencji w całym procesie komputacyjnym SI ludzki pracownik nigdy nie wyszedł z obiegu, a dokładniej mówiąc, nigdy nie opuścił linii montażowej. Mary Gray i Siddharth Suri ukuli termin „praca widmo” na określenie niewidzialnej pracy, która sprawia, że sztuczna inteligencja wydaje się sztucznie autonomiczna.
Za wyjątkiem zdolności do podjęcia kilku prostych decyzji dzisiejsza SI nie jest w stanie funkcjonować bez ingerencji człowieka. Czy chodzi o dostarczenie odpowiedniego przeglądu informacji, czy też o realizację skomplikowanego zamówienia pizzy poprzez usługę tekstową, kiedy sztuczna inteligencja napotyka na przeszkodę lub nie jest w stanie dokończyć zadania, tysiące firm wzywają ludzi do cichego ukończenia projektu. Ta nowa cyfrowa linia montażowa gromadzi wspólny wkład rozproszonych pracowników, dostarcza raczej części składowe niż całe produkty i działa w wielu sektorach gospodarki o każdej porze dnia i nocy.
Automatyzacja to mit; ponieważ maszyny, w tym sztuczna inteligencja, nieustannie potrzebują pomocy ze strony ludzi, niektórzy autorzy sugerują zastąpienie pojęcia „automatyzacja” bardziej adekwatnym pojęciem heteromatyzacja[71]. Heteromatyzacja oznacza, że znana opowieść o SI jako perpetuum mobile jest możliwa tylko dzięki rezerwowej armii robotników.
Istnieje jednak głębszy sposób, w jaki praca formuje sztuczną inteligencję. Źródło informacji uczenia maszynowego (niezależnie od tego, czy nazwiemy je: „dane wejściowe”, „dane treningowe”, czy po prostu „dane”) zawsze jest reprezentacją ludzkich umiejętności, działań i zachowań – produkcji społecznej w ogóle. Wszystkie zestawy danych treningowych są pośrednio diagramem podziału pracy ludzkiej, który sztuczna inteligencja musi przeanalizować i zautomatyzować. Na przykład zbiory danych do rozpoznawania obrazów to zapis pracy wzrokowej, jaką wykonują kierowcy, strażnicy i nadzorcy w ramach swoich zadań. Nawet naukowe zbiory danych opierają się na pracy naukowej, planowaniu eksperymentów, organizacji laboratorium i obserwacji analitycznej. Przepływ informacji w SI należy rozumieć jako aparat zaprojektowany do ekstrahowania „inteligencji analitycznej” z najróżniejszych form pracy i przenoszenia takiej inteligencji do maszyny (oczywiście obejmując, w ramach definicji pracy, rozszerzone formy produkcji społecznej, kulturowej i naukowej)[72]. W skrócie, źródłem inteligencji maszynowej jest podział pracy, a jej głównym celem jest automatyzacja pracy.
Badacze historii komputacji zauważali wczesne etapy inteligencji maszynowej już w dziewiętnastowiecznym projekcie mechanizacji podziału pracy umysłowej, a konkretnie w zadaniach polegających na ręcznych obliczeniach[73]. Przemysł komputacyjny był od tego czasu połączeniem nadzoru i dyscyplinowania pracy, optymalnego obliczania wartości dodatkowej i planowania zachowań zbiorowych[74]. Komputacja została ustanowiona nie jedynie przez logiczne rozumowanie, lecz przez reżim widoczności i zrozumiałości – który sama wzmacnia. Genealogię sztucznej inteligencji jako aparatu władzy potwierdza dziś jej powszechne zastosowanie w technologiach identyfikacji i przewidywania, jednak podstawową anomalią, która zawsze pozostaje do obliczenia, jest dezorganizacja pracy.
Sztuczna inteligencja jako technologia automatyzacji będzie miała ogromny wpływ na rynek pracy. Jeśli na przykład współczynnik błędu w rozpoznawaniu obrazów przy zastosowaniu uczenia głębokiego wynosi 1%, oznacza to, że wykonawców około 99% rutynowych prac opartych na zadaniach wzrokowych (na przykład ochrona lotniskowa) można zastąpić (przy założeniu, że nie przeszkodzą w tym prawne restrykcje ani związki zawodowe). Wpływ sztucznej inteligencji na pracę został dobrze opisany (wreszcie również z perspektywy pracowników) w artykule Europejskiego Instytutu Związków Zawodowych, w którym wyróżniono „siedem podstawowych wymiarów, które powinny zostać uwzględnione w przyszłych przepisach w celu ochrony pracowników: 1) zapewnienie ochrony prywatności pracowników oraz ochrony danych; 2) przyjrzenie się problemowi nadzoru, śledzenia i monitorowania; 3) uczynienie transparentnym celu algorytmów SI; 4) zapewnienie wykonalności „prawa do wyjaśnienia” decyzji podejmowanych przez algorytmy lub modele uczenia maszynowego; 5) zapewnienie bezpieczeństwa i ochrony pracownikom w kontaktach człowiek–maszyna; 6) zwiększanie autonomii pracowników w interakcji człowiek–maszyna; 7) umożliwienie pracownikom zdobycia umiejętności potrzebnych do pracy ze sztuczną inteligencją”[75].
Ostatecznie nooskop opowiada się za zadaniem nowego „Pytania o maszynę” w erze SI. „Pytanie o maszynę” było debatą, która wybuchła w Anglii podczas rewolucji przemysłowej. Wówczas odpowiedzią na wdrożenie maszyn i późniejsze bezrobocie technologiczne robotników była kampania społeczna na rzecz większej edukacji na temat maszyn. Kampania przybrała formę ruchu, który dał początek instytutom mechaniki[76]. Dziś potrzebne jest „pytanie o inteligentną maszynę”, aby rozwinąć więcej kolektywnej inteligencji na temat „inteligencji maszynowej”, więcej publicznej edukacji zamiast „uczących się maszyn” wraz z ich reżimem ekstraktywizmu wiedzy (który wzmacnia stare, kolonialne szlaki, o czym można się przekonać, jeśli przyjrzymy się mapie zależności na platformach crowdsourcingowych). Ponadto na globalnej Północy należy wysunąć na pierwszy plan tę kolonialną relację między korporacyjną sztuczną inteligencją a wytwarzaniem wiedzy jako dobra wspólnego. Celem nooskopu jest odsłonięcie ukrytego miejsca korporacyjnego „Mechanicznego Turka” i naświetlenie roli niewidzialnej pracy, która sprawia, że inteligencja maszyny wydaje się ideologicznie żywa.
- Na temat autonomii technologii zob. Langdon Winner, Autonomous Technology: Technics-Out-of-Control as a Theme in Political Thought, MIT Press, Cambridge, MA 2001. ↑
- O rozszerzeniu władzy kolonialnej na operacje logistyczne, algorytmy i finanse zob. Sandro Mezzadra, Brett Neilson, The Politics of Operations: Excavating Contemporary Capitalism, Duke University Press, Durham 2019. Na temat epistemicznego kolonializmu AI – zob. Matteo Pasquinelli, Three Thousand Years of Algorithmic Rituals: The Emergence of AI from the Computation of Space, „e-flux” 2019, nr 101, https://www.e-flux.com/journal/101/273221/three-thousand-years-of-algorithmic-rituals-the-emergence-of-ai-from-the-computation-of-space/ [dostęp: 28.05.2022]. ↑
- W humanistyce cyfrowej funkcjonuje pojęcie czytania zapośredniczonego, dzięki któremu powoli zaczęto angażować analizę danych i uczenie maszynowe w historię literatury i sztuki. Zob. Franco Moretti, Distant Reading, Verso, London 2013. ↑
- Wynalezienie znaków graficznych lub umownych [przyp. tłum.]. ↑
- Gottfried W. Leibniz, Przedmowa do nauki ogólnej [1677], w: tegoż, Wyznanie wiary filozofa…, przeł. S. Cichowicz i in., Warszawa, PWN 1969, s. 74. ↑
- Angielske słowo bias tłumaczymy w zależności od kontekstu jako błąd (systematyczny), stronniczość, ludzkie uprzedzenie. W polskiej literaturze dotyczącej uczenia maszynowego pojawia się termin obciążenie modelu, który nie oddaje wszystkich sensów słowa bias tak, jak używają go Autorzy [przyp. tłum.]. ↑
- Aby uzyskać więcej informacji na temat zwięzłej historii SI zob. Dominique Cardon, Jean-Philippe Cointet, Antoine Mazières, Neurons Spike Back: The Invention of Inductive Machines and the Artificial Intelligence Controversy, „Réseaux” 2018, nr 211. ↑
- Alexander Campolo, Kate Crawford, Enchanted Determinism: Power without Control in Artificial Intelligence, „Engaging Science, Technology, and Society” 2020, nr 6, https://estsjournal.org/index.php/ests/article/view/277 [dostęp: 28.05.2022]. ↑
- Zastosowanie analogii wizualnej ma na celu również to, by uchwycić zanikające rozróżnienie pomiędzy obrazem a logiką, reprezentacją i wnioskowaniem, w technicznej konstrukcji SI. Modele statystyczne uczenia maszynowego są reprezentacjami operacyjnymi (w rozumieniu takim jak obrazy operacyjne u Haruna Farockiego). ↑
- O systematycznym studium logicznych ograniczeń uczenia maszynowego zob. Momin Mailk, A Hierarchy of Limitations in Machine Learning, Arxiv preprint, 2020, https://arxiv.org/abs/2002.05193 ↑
- Na temat bardziej szczegółowej listy błędów SI zob. John Guttag, Harini Suresh, A Framework for Understanding Unintended Consequences of Machine Learning, Arxiv preprint, 2019, https://arxiv.org/abs/1901.10002. Zob. także: Aram Galstyan, Kristin Lerman, Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, A Survey on Bias and Fairness in Machine Learning, Arxiv preprint, 2019, https://arxiv.org/abs/1908.09635 ↑
- Virginia Eubanks, Automating Inequality, St. Martin’s Press, New York 2018. Zob. także: Kate Crawford, The Trouble with Bias, Keynote lecture, Conference on Neural Information Processing Systems, 2017. ↑
- Za Wikipedią: Prawa Jima Crowa (ang. Jim Crow laws) — regulacje wprowadzane głównie w południowych stanach Ameryki po wojnie secesyjnej. Miały za zadanie ograniczenie praw byłych czarnoskórych niewolników oraz pogłębianie separacji między białą a czarną ludnością w tych stanach. Do tego faktu historycznego odnosi się Michelle Alexander w książce The New Jim Crow: Mass Incarceration in the Age of Colorblindness [przyp. tłum.]. ↑
- Ruha Benjamin, Race After Technology: Abolitionist Tools for the New Jim Code, Polity, Cambridge, UK 2019, s. 5. ↑
- Informatycy przekonują, że SI jest zagadnieniem z dziedziny przetwarzania sygnałów, a konkretnie z poddziedziny kompresji danych. ↑
- Matteo Pasquinelli, The Eye of the Master, Verso, London [w przygotowaniu]. ↑
- Projekty takie jak między innymi wytłumaczalna sztuczna inteligencja czy interpretowalne uczenie głębokie i mapy cieplne udowodniły, że przebicie się do „czarnej skrzynki” uczenia maszynowego jest możliwe. Niemniej jednak pełna interpretowalność i wytłumaczalność modeli statystycznych uczenia maszynowego pozostaje mitem. Zob. Zacharay Lipton, The Mythos of Model Interpretability, ArXiv preprint, 2016, https://arxiv.org/abs/1606.03490 ↑
- Antonella Corsani, Bernard Paulré, Carlo Vercellone, Jean-Marie Monnier, Maurizio Lazzarato, Patrick Dieuaide, Yann Moulier-Boutang, Le Capitalisme cognitif comme sortie de la crise du capitalisme industriel. Un programme de recherché, Laboratoire Isys Matisse, Maison des Sciences Economiques, Paris 2004. Zob. także: Shoshana Zuboff, The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power, Profile Books, London 2019. ↑
- Raw Data is an Oxymoron, ed. Lisa Gitelman, MIT Press, Cambridge, MA 2013. ↑
- In supervised learning. Also self-supervised learning maintains forms of human intervention. ↑
- Na temat taksonomii jako formy wiedzy i siły zob. Michel Foucault, The Order of Things, Routledge, London 2005. ↑
- Na przykład stworzony przez Amazon Mechaniczny Turek, cynicznie nazwany przez Jeffa Bezosa „sztuczną sztuczną inteligencją”. Zob. Jason Pontin, Artificial Intelligence, With Help from the Humans, „The New York Times”, 25.03.2007. ↑
- Chociaż architektura konwolucyjna sięga czasów prac Yanna LeCunna pod koniec lat osiemdziesiątych, uczenie głębokie zaczęło się od tego artykułu: Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, ImageNet Classification with Deep Convolutional Neural Networks, „Communications of the ACM” 2017, nr 60 (6). ↑
- Dla przystępnych (ale niezbyt krytycznych) uwag na temat rozwoju ImageNetu zob. Melanie Mitchell, Artificial Intelligence: A Guide for Thinking Humans, Penguin, London 2019. ↑
- WordNet jest „leksykalną bazą danych relacji semantycznych między słowami”, która została zapoczątkowana przez George’a Armitage’a na Uniwersytecie Princeton w 1985 roku. Zapewnia ona ścisłą drzewiastą strukturę definicji. ↑
- Kate Crawford, Trevor Paglen, Excavating AI: The Politics of Training Sets for Machine Learning, 19.09.2019, https://excavating.ai ↑
- Adam Harvey, Jules LaPlace, Megapixel project, 2019. https://megapixels.cc/about/ oraz Madhumita Murgia, Who’s Using Your Face? The Ugly Truth About Facial Recognition, „Financial Times”, 19.04.2019. ↑
- Ogólne rozporządzenie o ochronie danych, które zostało przyjęte przez Parlament Europejski w maju 2018, jest mimo wszystko krokiem naprzód w porównaniu do wciąż trwającego braku regulacji w Stanach Zjednoczonych. ↑
- Frank Rosenblatt, The Perceptron: A Perceiving and Recognizing Automaton, Cornell Aeronautical Laboratory, „Report” nr 85-460-1, Buffalo 1957. ↑
- Warren McCulloch, Walter Pitts, How We Know Universals: The Perception of Auditory and Visual Forms, „The Bulletin of Mathematical Biophysics” 1947, nr 9 (3). ↑
- Ang. AGI – Artificial General Intelligence [przyp. tłum.]. ↑
- Parametry modelu wyuczone z danych nazywa się parametrami, natomiast te parametry, które nie są wyuczone z danych, lecz ustawione ręcznie, nazywa się hiperparametrami (określają one liczbę i właściwości parametrów). ↑
- Rozwiązanie to może być także wyrażone procentowo i przyjmować wartość pomiędzy 0 a 1. ↑
- https://keras.io/applications (dokumentacja poszczególnych modeli). ↑
- Paul Edwards, A Vast Machine: Computer Models, Climate Data, and The Politics of Global Warming, The MIT Press, Cambridge, MA 2010. ↑
- Zob. także Wspólny Model Ziemskiego Systemu Klimatycznego (ang. Community Earth System Model [CESM]) tworzony od 1996 roku przez Narodowe Centrum Badań Atmosferycznych (NCAR) w Bolder, Kolorado. Community Earth System Model to w pełni sprzężona symulacja numeryczna systemu Ziemi, składająca się z atmosfery, oceanu, lodu, powierzchni lądu, obiegu węgla i innych elementów. CESM zawiera model klimatyczny zapewniający najnowocześniejsze symulacje przeszłości, teraźniejszości i przyszłości Ziemi. http://www.cesm.ucar.edu ↑
- George Box, Robustness in the Strategy of Scientific Model Building, Technical Report #1954, Mathematics Research Center, University of Wisconsin-Madison, 1979. ↑
- Postkolonialne oraz poststrukturalistyczne szkoły antropologiczne i etnologiczne podkreślały, że nigdy nie istnieje terytorium per se, ale zawsze występuje także akt terytorializacji. ↑
- Rozpoznawanie wzorców jest jednym z aspektów ekonomii uwagi. „Patrzeć znaczy pracować”, jak przypomina nam Jonathan Beller. Jonathan Beller, The Cinematic Mode of Production: Attention Economy and the Society of the Spectacle, University Press of New England, Lebanon, NH 2006, s. 2. ↑
- Dan McQuillan, Manifesto on Algorithmic Humanitarianism. Zaprezentowane na sympozjum Reimagining Digital Humanitarianism, Goldsmiths, University of London, 16.02.2018. ↑
- Co zostało udowodnione przez twierdzenie o uniwersalnej aproksymacji. ↑
- Ananya Ganesh, Andrew McCallum i Emma Strubell, Energy and Policy Considerations for Deep Learning in NLP, ArXiv preprint, 2019, https://arxiv.org/abs/1906.02243 ↑
- Dominique Cardon, Jean-Philippe Cointet, Antoine Mazières, Neurons Spike Back… ↑
- William Gibson Neuromancer, w: tegoż, Trylogia Ciągu, przeł. Piotr W. Cholewa, Wydawnictwo MAG, Warszawa 2015, s. 58. ↑
- Źródło: corpling.hypotheses.org/495 ↑
- Jamie Morgenstern, Samira Samadi, Mohit Singh, Uthaipon Tantipongpipat, Santosh Vempala, The Price of Fair PCA: One Extra Dimension, „Advances in Neural Information Processing Systems” 2018, nr 31. ↑
- O idei wspomaganego i generatywnego tworzenia zob. Roelof Pieters, Samim Winiger, Creative AI: On the Democratisation and Escalation of Creativity, 2016, http://www.medium.com/@creativeai/creativeai-9d4b2346faf3 ↑
- Os Keyes, The Misgendering Machines: Trans/HCI Implications of Automatic Gender Recognition, „Proceedings of the ACM on Human-Computer Interaction’ 2018, nr 2 (88), https://doi.org/10.1145/3274357 ↑
- Alexander Mordvintsev, Christophe Olah, Mike Tyka, Inceptionism: Going Deeper into Neural Networks, Google Research blog, 17.06.2015, https://ai.googleblog.com/2015/06/ inceptionism-going-deeper-into-neural.html ↑
- Deepfaki są to spreparowane dzieła, takie jak na przykład filmy, w których twarz danej osoby jest podmieniona na twarz kogoś innego, często w celu wytworzenia fake newsów. ↑
- Joseph Paul Cohen, Sina Honari, Margaux Luck, Distribution Matching Losses Can Hallucinate Features in Medical Image Translation, International Conference on Medical Image Computing and Computer-Assisted Intervention, Cham, ArXiv preprint 2018, https://arxiv.org/abs/1805.08841 ↑
- Fabian Offert, Neural Network Cultures panel, Transmediale festival and KIM HfG Karlsruhe, Berlin, 1.02.2020, http://kim.hfg-karlsruhe.de/events/neuralnetwork-cultures ↑
- Michel Foucault, Abnormal: Lectures at the Collège de France 1974–1975, Picador, New York 2004, s. 26. ↑
- Na temat norm komputacyjnych zob. Matteo Pasquinelli, Arcana Mathematica Imperii: The Evolution of Western Computational Norms, w: Former West, eds. Maria Hlavajova i in., MIT Press, Cambridge, MA 2017. ↑
- Paola Ricaurte, Data Epistemologies, The Coloniality of Power, and Resistance, „Television & New Media”, 7.03.2019. ↑
- David Ingold, Spencer Soper, Amazon Doesn’t Consider the Race of its Customers. Should It?, Bloomberg, 21.04.2016, https://www.bloomberg.com/graphics/2016-amazon-same-day ↑
- Cathy O’Neil, Weapons of Math Destruction, Broadway Books, New York 2016, ch. 9. ↑
- Chris Anderson, The End of Theory: The Data Deluge Makes the Scientific Method Obsolete, „Wired”, 23.06.2008. Dla krytycznych uwag zob.: Fulvio Mazzocchi, Could Big Data Be the End of Theory in Science? A Few Remarks on the Epistemology of Data-Driven Science, „EMBO Reports” 2015, nr 16 (10), https://www.embopress.org/doi/full/10.15252/embr.201541001 [dostęp: 28.05.2022]. ↑
- Judea Pearl, Dana Mackenzie, The Book of Why: The New Science of Cause and Effect, Basic Books, New York 2018. ↑
- Eksperymenty nowojorskiej policji (NYPD) mają miejsce już od późnych lat osiemdziesiątych. Zob. Matteo Pasquinelli, Arcana Mathematica Imperii… ↑
- Dan McQuillan, People’s Councils for Ethical Machine Learning, „Social Media and Society” 2018, nr 4 (2). ↑
- Paola Ricaurte, Data Epistemologies… ↑
- Felix Guattari, Schizoanalytic Cartographies, Continuum, London 2013, s. 2. ↑
- Związek między SI a hakowaniem nie jest tak odległy jak mogłoby się wydawać: często sprowadza się on do pętli wzajemnego uczenia się, oceny i wzmocnienia. ↑
- Adam Harvey, HyperFace project, 2016. https://ahprojects.com/hyperface ↑
- Anish Athalye i in., Synthesizing Robust Adversarial Examples, ArXiv preprint, 2017. https://arxiv.org/abs/1707.07397 ↑
- Nir Morgulis i in., Fooling a Real Car with Adversarial Traffic Signs, ArXiv preprint, 2019, https://arxiv.org/abs/1907.00374 ↑
- Zatruwanie danych może być także wykorzystanie w celu ochrony prywatności poprzez wprowadzanie anonimowych lub losowych informacji do zbioru danych. ↑
- Ian Goodfellow i in., Explaining and Harnessing Adversarial Examples, ArXiv preprint, 2014, https://arxiv.org/abs/1412.6572 ↑
- Florian Schmidt, Crowdsourced Production of AI Training Data: How Human Workers Teach Self-Driving Cars to See, Hans-Böckler-Stiftung, Düsseldorf 2019. ↑
- Hamid Ekbia, Bonnie Nardi, Heteromation, and Other Stories of Computing and Capitalism, MIT Press, Cambridge, MA 2017. ↑
- O idei inteligencji analitycznej zob. Lorraine Daston, Calculation and the Division of Labour 1750–1950, „Bulletin of the German Historical Institute” 2018, nr 62. ↑
- Simon Schaffer, Babbage’s Intelligence: Calculating Engines and the Factory System, „Critical Inquiry” 1994, nr 1 (21); Lorraine Daston, Enlightenment calculations, „Critical Inquiry” 1994, nr 1 (21), 1994; Matthew L. Jones, Reckoning with Matter: Calculating Machines, Innovation, and Thinking about Thinking from Pascal to Babbage, University of Chicago Press, Chicago 2016, s. 62. ↑
- Matteo Pasquinelli, On the Origins of Marx’s General Intellect, „Radical Philosophy”, 2.06.2019. ↑
- Aida Ponce, Labour in the Age of AI: Why Regulation is Needed to Protect Workers, ETUI Research Paper – Foresight Brief 8, 2020, http://dx.doi.org/10.2139 /ssrn.3541002 ↑
- Maxine Berg, The Machinery Question and the Making of Political Economy, Cambridge University Press, Cambridge, UK 1980. W rzeczywistości „The Economist” przestrzegał niedawno przed „powrotem pytania o maszynę” w erze sztucznej inteligencji. Zob. Tom Standage, The Return of the Machinery Question, „The Economist”, 23.06.2016. ↑
Podziękowania
Podziękowania autorów: Jon Beller, Kate Crawford, Dubravko Ćulibrk, Ariana Dongus, Claire Glanois, Adam Harvey, Leonardo Impett, Arif Kornweitz, Wietske Maas, Dan McQuillan, Fabian Offert, Godofredo Pereira, Johannes Paul Raether, Natascha Sadr Haghighian, Olivia Solis, Mitch Speed i całej społeczności wokół KIM HfG Karlsruhe za wkład i komentarze.
Podziękowania tłumaczy: Alexander Juda, Aleksandra Kleczka, Dawid Prząda.


Polskie tłumaczenie Grupa Robocza, w ramach programu Minimum Viable Utopia.
Vladan Joler jest naukowcem, badaczem i artystą mieszkającym w Nowym Sadzie. W swojej pracy łączy badania nad danymi, kontrkartografię, dziennikarstwo śledcze, pisarstwo, wizualizację danych, projektowanie krytyczne i wiele innych dyscyplin. Bada i wizualizuje różne techniczne i społeczne aspekty przejrzystości algorytmów, cyfrowego wyzysku pracowników, niewidzialnych infrastruktur i wielu innych współczesnych zjawisk na styku technologii i społeczeństwa. W 2018 roku, we współpracy z Kate Crawford, opublikował Anatomy of an AI System – wielkoskalową mapę i rozbudowany esej, w których badał ludzką pracę, dane i zasoby planetarne wymagane do zbudowania i obsługi urządzenia Amazon Echo. Jego poprzednie opracowanie, zatytułowane Fabryka algorytmów Facebooka, obejmowało pogłębione badania kryminalistyczne i wizualne mapowanie procesów algorytmicznych oraz form wyzysku stojących za tym największym portalem społecznościowym. Inne jego badania, które zostały opublikowane w ostatnich latach przez niezależny kolektyw badawczy SHARE Lab, skupiają się na wojnie informacyjnej, analizie metadanych, wykorzystywaniu historii przeglądania, inwigilacji i architekturze internetu.
Jest kuratorem i organizatorem licznych wydarzeń i spotkań internetowych aktywistów, artystów i badaczy, w tym wydarzeń SHARE w Belgradzie i Bejrucie. Jego artystyczne korzenie sięgają aktywizmu medialnego oraz hakowania gier.
Matteo Pasquinelli (PhD) mieszka w Berlinie i jest profesorem filozofii mediów na Uniwersytecie Sztuki i Projektowania w Karlsruhe, gdzie koordynuje grupę badawczą KIM zajmującą się sztuczną inteligencją i filozofią mediów. Zredagował antologię Alleys of Your Mind. Augmented Intelligence and Its Traumas (Meson Press, Lüneburg 2015) oraz, wraz z Vladanem Jolerem, jest współautorem eseju wizualnego Nooskop ujawniony – manifest. Sztuczna inteligencja jako narzędzie ekstraktywizmu wiedzy (https://nooskop.mvu.pl). Jego badania skupiają się na przecięciu nauk kognitywnych, gospodarki cyfrowej i inteligencji maszyn. Dla wydawnictwa Verso Books przygotowuje monografię na temat historii SI zatytułowaną The Eye of the Master.